Tutorial
In this example, we’ll explore a common approach that is particularly useful in real-world applications: take a pre-trained Caffe network and fine-tune the parameters on your custom data.
The advantage of this approach is that, since pre-trained networks are learned on a large set of images, the intermediate layers capture the “semantics” of the general visual appearance. Think of it as a very powerful generic visual feature that you can treat as a black box. On top of that, only a relatively small amount of data is needed for good performance on the target task.
First, we will need to prepare the data. This involves the following parts:
(1) Get the ImageNet ilsvrc pretrained model with the provided shell scripts.
(2) Download a subset of the overall Flickr style dataset for this demo.
(3) Compile the downloaded Flickr dataset into a database that Caffe can then consume.
1 | caffe_root = '../' # this file should be run from {caffe_root}/examples (otherwise change this line) |
Setup and dataset download
Download data required for this exercise.
get_ilsvrc_aux.shto download the ImageNet data mean, labels, etc.download_model_binary.pyto download the pretrained reference modelfinetune_flickr_style/assemble_data.pydownloads the style training and testing data
We’ll download just a small subset of the full dataset for this exercise: just 2000 of the 80K images, from 5 of the 20 style categories. (To download the full dataset, set full_dataset = True in the cell below.)
1 | # Download just a small subset of the data for this exercise. |
Downloading...
--2016-02-24 00:28:36-- http://dl.caffe.berkeleyvision.org/caffe_ilsvrc12.tar.gz
Resolving dl.caffe.berkeleyvision.org (dl.caffe.berkeleyvision.org)... 169.229.222.251
Connecting to dl.caffe.berkeleyvision.org (dl.caffe.berkeleyvision.org)|169.229.222.251|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 17858008 (17M) [application/octet-stream]
Saving to: ‘caffe_ilsvrc12.tar.gz’
100%[======================================>] 17,858,008 112MB/s in 0.2s
2016-02-24 00:28:36 (112 MB/s) - ‘caffe_ilsvrc12.tar.gz’ saved [17858008/17858008]
Unzipping...
Done.
Model already exists.
Downloading 2000 images with 7 workers...
Writing train/val for 1996 successfully downloaded images.
Define weights, the path to the ImageNet pretrained weights we just downloaded, and make sure it exists.
1 | import os |
Load the 1000 ImageNet labels from ilsvrc12/synset_words.txt, and the 5 style labels from finetune_flickr_style/style_names.txt.
1 | # Load ImageNet labels to imagenet_labels |
Loaded ImageNet labels:
n01440764 tench, Tinca tinca
n01443537 goldfish, Carassius auratus
n01484850 great white shark, white shark, man-eater, man-eating shark, Carcharodon carcharias
n01491361 tiger shark, Galeocerdo cuvieri
n01494475 hammerhead, hammerhead shark
n01496331 electric ray, crampfish, numbfish, torpedo
n01498041 stingray
n01514668 cock
n01514859 hen
n01518878 ostrich, Struthio camelus
...
Loaded style labels:
Detailed, Pastel, Melancholy, Noir, HDR
Defining and running the nets
We’ll start by defining caffenet, a function which initializes the CaffeNet architecture (a minor variant on AlexNet), taking arguments specifying the data and number of output classes.
1 | from caffe import layers as L |
Now, let’s create a CaffeNet that takes unlabeled “dummy data” as input, allowing us to set its input images externally and see what ImageNet classes it predicts.
1 | dummy_data = L.DummyData(shape=dict(dim=[1, 3, 227, 227])) |
Define a function style_net which calls caffenet on data from the Flickr style dataset.
The new network will also have the CaffeNet architecture, with differences in the input and output:
- the input is the Flickr style data we downloaded, provided by an
ImageDatalayer - the output is a distribution over 20 classes rather than the original 1000 ImageNet classes
- the classification layer is renamed from
fc8tofc8_flickrto tell Caffe not to load the original classifier (fc8) weights from the ImageNet-pretrained model
1 | def style_net(train=True, learn_all=False, subset=None): |
Use the style_net function defined above to initialize untrained_style_net, a CaffeNet with input images from the style dataset and weights from the pretrained ImageNet model.
Call forward on untrained_style_net to get a batch of style training data.
1 | untrained_style_net = caffe.Net(style_net(train=False, subset='train'), |
Pick one of the style net training images from the batch of 50 (we’ll arbitrarily choose #8 here). Display it, then run it through imagenet_net, the ImageNet-pretrained network to view its top 5 predicted classes from the 1000 ImageNet classes.
Below we chose an image where the network’s predictions happen to be reasonable, as the image is of a beach, and “sandbar” and “seashore” both happen to be ImageNet-1000 categories. For other images, the predictions won’t be this good, sometimes due to the network actually failing to recognize the object(s) present in the image, but perhaps even more often due to the fact that not all images contain an object from the (somewhat arbitrarily chosen) 1000 ImageNet categories. Modify the batch_index variable by changing its default setting of 8 to another value from 0-49 (since the batch size is 50) to see predictions for other images in the batch. (To go beyond this batch of 50 images, first rerun the above cell to load a fresh batch of data into style_net.)
1 | def disp_preds(net, image, labels, k=5, name='ImageNet'): |
1 | batch_index = 8 |
actual label = Melancholy

1 | disp_imagenet_preds(imagenet_net, image) |
top 5 predicted ImageNet labels =
(1) 69.89% n09421951 sandbar, sand bar
(2) 21.76% n09428293 seashore, coast, seacoast, sea-coast
(3) 3.22% n02894605 breakwater, groin, groyne, mole, bulwark, seawall, jetty
(4) 1.89% n04592741 wing
(5) 1.23% n09332890 lakeside, lakeshore
We can also look at untrained_style_net‘s predictions, but we won’t see anything interesting as its classifier hasn’t been trained yet.
In fact, since we zero-initialized the classifier (see caffenet definition – no weight_filler is passed to the final InnerProduct layer), the softmax inputs should be all zero and we should therefore see a predicted probability of 1/N for each label (for N labels). Since we set N = 5, we get a predicted probability of 20% for each class.
1 | disp_style_preds(untrained_style_net, image) |
top 5 predicted style labels =
(1) 20.00% Detailed
(2) 20.00% Pastel
(3) 20.00% Melancholy
(4) 20.00% Noir
(5) 20.00% HDR
We can also verify that the activations in layer fc7 immediately before the classification layer are the same as (or very close to) those in the ImageNet-pretrained model, since both models are using the same pretrained weights in the conv1 through fc7 layers.
1 | diff = untrained_style_net.blobs['fc7'].data[0] - imagenet_net.blobs['fc7'].data[0] |
Delete untrained_style_net to save memory. (Hang on to imagenet_net as we’ll use it again later.)
1 | del untrained_style_net |
Training the style classifier
Now, we’ll define a function solver to create our Caffe solvers, which are used to train the network (learn its weights). In this function we’ll set values for various parameters used for learning, display, and “snapshotting” – see the inline comments for explanations of what they mean. You may want to play with some of the learning parameters to see if you can improve on the results here!
1 | from caffe.proto import caffe_pb2 |
Now we’ll invoke the solver to train the style net’s classification layer.
For the record, if you want to train the network using only the command line tool, this is the command:
1 | build/tools/caffe train \ |
However, we will train using Python in this example.
We’ll first define run_solvers, a function that takes a list of solvers and steps each one in a round robin manner, recording the accuracy and loss values each iteration. At the end, the learned weights are saved to a file.
1 | def run_solvers(niter, solvers, disp_interval=10): |
Let’s create and run solvers to train nets for the style recognition task. We’ll create two solvers – one (style_solver) will have its train net initialized to the ImageNet-pretrained weights (this is done by the call to the copy_from method), and the other (scratch_style_solver) will start from a randomly initialized net.
During training, we should see that the ImageNet pretrained net is learning faster and attaining better accuracies than the scratch net.
1 | niter = 200 # number of iterations to train |
Running solvers for 200 iterations...
1) pretrained: loss=1.609, acc=28%; scratch: loss=1.609, acc=28%
1) pretrained: loss=1.293, acc=52%; scratch: loss=1.626, acc=14%
2) pretrained: loss=1.110, acc=56%; scratch: loss=1.646, acc=10%
3) pretrained: loss=1.084, acc=60%; scratch: loss=1.616, acc=20%
4) pretrained: loss=0.898, acc=64%; scratch: loss=1.588, acc=26%
5) pretrained: loss=1.024, acc=54%; scratch: loss=1.607, acc=32%
6) pretrained: loss=0.925, acc=66%; scratch: loss=1.616, acc=20%
7) pretrained: loss=0.861, acc=74%; scratch: loss=1.598, acc=24%
8) pretrained: loss=0.967, acc=60%; scratch: loss=1.588, acc=30%
9) pretrained: loss=1.274, acc=52%; scratch: loss=1.608, acc=20%
1) pretrained: loss=1.113, acc=62%; scratch: loss=1.588, acc=30%
2) pretrained: loss=0.922, acc=62%; scratch: loss=1.578, acc=36%
3) pretrained: loss=0.918, acc=62%; scratch: loss=1.599, acc=20%
4) pretrained: loss=0.959, acc=58%; scratch: loss=1.594, acc=22%
5) pretrained: loss=1.228, acc=50%; scratch: loss=1.608, acc=14%
6) pretrained: loss=0.727, acc=76%; scratch: loss=1.623, acc=16%
7) pretrained: loss=1.074, acc=66%; scratch: loss=1.607, acc=20%
8) pretrained: loss=0.887, acc=60%; scratch: loss=1.614, acc=20%
9) pretrained: loss=0.961, acc=62%; scratch: loss=1.614, acc=18%
10) pretrained: loss=0.737, acc=76%; scratch: loss=1.613, acc=18%
11) pretrained: loss=0.836, acc=70%; scratch: loss=1.614, acc=16%
Done.
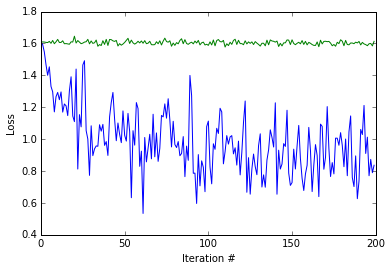
Let’s look at the training loss and accuracy produced by the two training procedures. Notice how quickly the ImageNet pretrained model’s loss value (blue) drops, and that the randomly initialized model’s loss value (green) barely (if at all) improves from training only the classifier layer.
1 | plot(np.vstack([train_loss, scratch_train_loss]).T) |
<matplotlib.text.Text at 0x7f75d49e1090>
1 | plot(np.vstack([train_acc, scratch_train_acc]).T) |
<matplotlib.text.Text at 0x7f75d49e1a90>
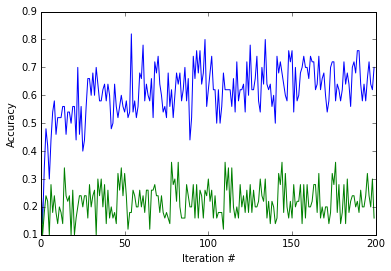
Let’s take a look at the testing accuracy after running 200 iterations of training. Note that we’re classifying among 5 classes, giving chance accuracy of 20%. We expect both results to be better than chance accuracy (20%), and we further expect the result from training using the ImageNet pretraining initialization to be much better than the one from training from scratch. Let’s see.
1 | def eval_style_net(weights, test_iters=10): |
1 | test_net, accuracy = eval_style_net(style_weights) |
Accuracy, trained from ImageNet initialization: 50.0%
Accuracy, trained from random initialization: 23.6%
End-to-end finetuning for style
Finally, we’ll train both nets again, starting from the weights we just learned. The only difference this time is that we’ll be learning the weights “end-to-end” by turning on learning in all layers of the network, starting from the RGB conv1 filters directly applied to the input image. We pass the argument learn_all=True to the style_net function defined earlier in this notebook, which tells the function to apply a positive (non-zero) lr_mult value for all parameters. Under the default, learn_all=False, all parameters in the pretrained layers (conv1 through fc7) are frozen (lr_mult = 0), and we learn only the classifier layer fc8_flickr.
Note that both networks start at roughly the accuracy achieved at the end of the previous training session, and improve significantly with end-to-end training. To be more scientific, we’d also want to follow the same additional training procedure without the end-to-end training, to ensure that our results aren’t better simply because we trained for twice as long. Feel free to try this yourself!
1 | end_to_end_net = style_net(train=True, learn_all=True) |
Running solvers for 200 iterations...
1) pretrained, end-to-end: loss=0.781, acc=64%; scratch, end-to-end: loss=1.585, acc=28%
1) pretrained, end-to-end: loss=1.178, acc=62%; scratch, end-to-end: loss=1.638, acc=14%
2) pretrained, end-to-end: loss=1.084, acc=60%; scratch, end-to-end: loss=1.637, acc= 8%
3) pretrained, end-to-end: loss=0.902, acc=76%; scratch, end-to-end: loss=1.600, acc=20%
4) pretrained, end-to-end: loss=0.865, acc=64%; scratch, end-to-end: loss=1.574, acc=26%
5) pretrained, end-to-end: loss=0.888, acc=60%; scratch, end-to-end: loss=1.604, acc=26%
6) pretrained, end-to-end: loss=0.538, acc=78%; scratch, end-to-end: loss=1.555, acc=34%
7) pretrained, end-to-end: loss=0.717, acc=72%; scratch, end-to-end: loss=1.563, acc=30%
8) pretrained, end-to-end: loss=0.695, acc=74%; scratch, end-to-end: loss=1.502, acc=42%
9) pretrained, end-to-end: loss=0.708, acc=68%; scratch, end-to-end: loss=1.523, acc=26%
1) pretrained, end-to-end: loss=0.432, acc=78%; scratch, end-to-end: loss=1.500, acc=38%
2) pretrained, end-to-end: loss=0.611, acc=78%; scratch, end-to-end: loss=1.618, acc=18%
3) pretrained, end-to-end: loss=0.610, acc=76%; scratch, end-to-end: loss=1.473, acc=30%
4) pretrained, end-to-end: loss=0.471, acc=78%; scratch, end-to-end: loss=1.488, acc=26%
5) pretrained, end-to-end: loss=0.500, acc=76%; scratch, end-to-end: loss=1.514, acc=38%
6) pretrained, end-to-end: loss=0.476, acc=80%; scratch, end-to-end: loss=1.452, acc=46%
7) pretrained, end-to-end: loss=0.368, acc=82%; scratch, end-to-end: loss=1.419, acc=34%
8) pretrained, end-to-end: loss=0.556, acc=76%; scratch, end-to-end: loss=1.583, acc=36%
9) pretrained, end-to-end: loss=0.574, acc=72%; scratch, end-to-end: loss=1.556, acc=22%
10) pretrained, end-to-end: loss=0.360, acc=88%; scratch, end-to-end: loss=1.429, acc=44%
11) pretrained, end-to-end: loss=0.458, acc=78%; scratch, end-to-end: loss=1.370, acc=44%
Done.
Let’s now test the end-to-end finetuned models. Since all layers have been optimized for the style recognition task at hand, we expect both nets to get better results than the ones above, which were achieved by nets with only their classifier layers trained for the style task (on top of either ImageNet pretrained or randomly initialized weights).
1 | test_net, accuracy = eval_style_net(style_weights_ft) |
Accuracy, finetuned from ImageNet initialization: 53.6%
Accuracy, finetuned from random initialization: 39.2%
We’ll first look back at the image we started with and check our end-to-end trained model’s predictions.
1 | plt.imshow(deprocess_net_image(image)) |
top 5 predicted style labels =
(1) 55.67% Melancholy
(2) 27.21% HDR
(3) 16.46% Pastel
(4) 0.63% Detailed
(5) 0.03% Noir

Whew, that looks a lot better than before! But note that this image was from the training set, so the net got to see its label at training time.
Finally, we’ll pick an image from the test set (an image the model hasn’t seen) and look at our end-to-end finetuned style model’s predictions for it.
1 | batch_index = 1 |
actual label = Pastel

1 | disp_style_preds(test_net, image) |
top 5 predicted style labels =
(1) 99.76% Pastel
(2) 0.13% HDR
(3) 0.11% Detailed
(4) 0.00% Melancholy
(5) 0.00% Noir
We can also look at the predictions of the network trained from scratch. We see that in this case, the scratch network also predicts the correct label for the image (Pastel), but is much less confident in its prediction than the pretrained net.
1 | disp_style_preds(scratch_test_net, image) |
top 5 predicted style labels =
(1) 49.81% Pastel
(2) 19.76% Detailed
(3) 17.06% Melancholy
(4) 11.66% HDR
(5) 1.72% Noir
Of course, we can again look at the ImageNet model’s predictions for the above image:
1 | disp_imagenet_preds(imagenet_net, image) |
top 5 predicted ImageNet labels =
(1) 34.90% n07579787 plate
(2) 21.63% n04263257 soup bowl
(3) 17.75% n07875152 potpie
(4) 5.72% n07711569 mashed potato
(5) 5.27% n07584110 consomme
So we did finetuning and it is awesome. Let’s take a look at what kind of results we are able to get with a longer, more complete run of the style recognition dataset. Note: the below URL might be occasionally down because it is run on a research machine.
Reference
History
- 20180808: created.