Guide
version
- gcc 4.8.5/5.4.0
- g++ 4.8.5/5.4.0
- cmake 3.2.2
- nvidia driver 396.54 + cuda 9.2 + cudnn 7.1.4
- protobuf 3.4.0
install nvidia-docker2
see nvidia-docker2 guide on ubuntu 16.04
test
1 | sudo docker run --runtime=nvidia --rm nvidia/cuda nvidia-smi |
build and run
build
1 | git clone https://github.com/PaddlePaddle/Anakin.git anakin |
error occur with cudnn. skip.
run
1 | ./anakin_docker_build_and_run.sh -p NVIDIA-GPU -o Ubuntu -m Run |
compile anakin
1 | sudo docker run -it --runtime=nvidia fdcda959f60a bin/bash |
build
1 | # 1. use script to build |
x86 build
1 | ./tools/x86_build.sh |
OK. no errors.
gpu build
1 | ./tools/gpu_build.sh |
build errors occur. no cudnn found.
compile anakin in host
install protobuf
install protobuf 3.4.0, see Part 1: compile protobuf-cpp on ubuntu 16.04
configure env
vim .bashrc
1 | # cuda for anakin |
source .bashrc
build anakin
x86 build
1 | git checkout developing |
OK. no errors.
if error occurs, then
1 | rm -rf CMakeFiles |
gpu build
1 | ./tools/gpu_build.sh |
gpu build with cmake
1 | cd anakin |
anakin overview
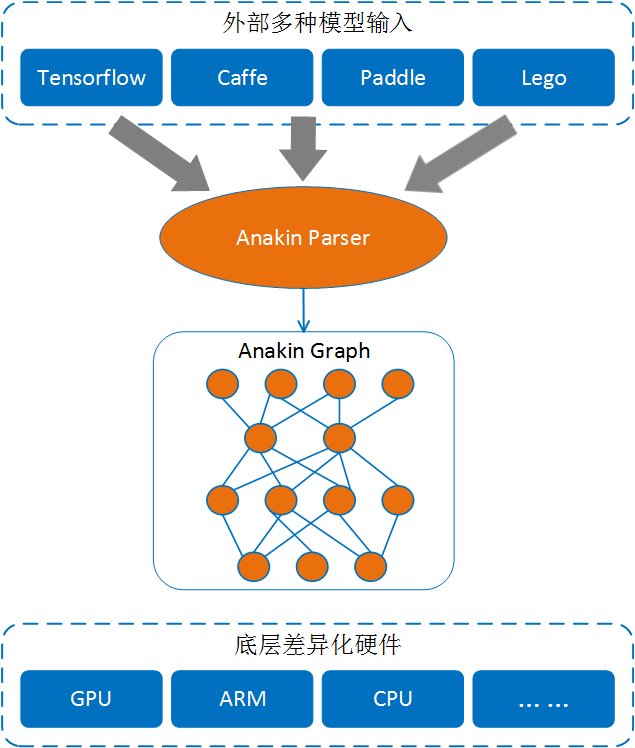
用Anakin来进行前向计算主要分为三个步骤:
- 将外部模型通过Anakin Parser解析为Anakin模型
- 加载Anakin模型生成原始计算图,然后需要对原始计算图进行优化。
- Anakin会选择不同硬件平台执行计算图。
Tensor
Tensor接受三个模板参数:
template<typename TargetType, DataType datatype, typename LayOutType = NCHW>
class Tensor .../* Inherit other class */{
//some implements
...
};
- TargetType是平台类型,如X86,GPU等等,在Anakin内部有相应的标识与之对应;
- datatype是普通的数据类型,在Anakin内部也有相应的标志与之对应;
- LayOutType是数据分布类型,如batch x channel x height x width [NxCxHxW], 在Anakin内部用一个struct来标识。 Anakin中数据类型与基本数据类型的对应如下:
TargetType
Anakin TargetType | platform
:—-: |
NV | NVIDIA GPU
ARM | ARM
AMD | AMD GPU
X86 | X86
NVHX86 | NVIDIA GPU with Pinned Memory
| Anakin DataType | C++ | Description |
|---|---|---|
| AK_HALF | short | fp16 |
| AK_FLOAT | float | fp32 |
| AK_DOUBLE | double | fp64 |
| AK_INT8 | char | int8 |
| AK_INT16 | short | int16 |
| AK_INT32 | int | int32 |
| AK_INT64 | long | int64 |
| AK_UINT8 | unsigned char | uint8 |
| AK_UINT16 | unsigned short | uint8 |
| AK_UINT32 | unsigned int | uint32 |
| AK_STRING | std::string | / |
| AK_BOOL | bool | / |
| AK_SHAPE | / | Anakin Shape |
| AK_TENSOR | / | Anakin Tensor |
LayOutType
| Anakin LayOutType ( Tensor LayOut ) | Tensor Dimention | Tensor Support | Op Support |
|---|---|---|---|
| W | 1-D | YES | NO |
| HW | 2-D | YES | NO |
| WH | 2-D | YES | NO |
| NW | 2-D | YES | YES |
| NHW | 3-D | YES | YES |
| NCHW ( default ) | 4-D | YES | YES |
| NHWC | 4-D | YES | NO |
| NCHW_C4 | 5-D | YES | YES |
理论上,Anakin支持申明1维以上的tensor,但是对于Anakin中的Op来说,只支持NW、NHW、NCHW、NCHW_C4这四种LayOut,其中NCHW是默认的LayOutType,NCHW_C4是专门针对于int8这种数据类型的。
Graph
Graph类负责加载Anakin模型生成计算图、对图进行优化、存储模型等操作。
template<typename TargetType, DataType Dtype, Precision Ptype>
class Graph ... /* inherit other class*/{
//some implements
...
};
load
//some declarations
...
auto graph = new Graph<NV, AK_FLOAT, Precision::FP32>();
std::string model_path = "the/path/to/where/your/models/are";
const char *model_path1 = "the/path/to/where/your/models/are";
//Loading Anakin model to generate a compute graph.
auto status = graph->load(model_path);
//Or this way.
auto status = graph->load(model_path1);
//Check whether load operation success.
if(!status){
std::cout << "error" << endl;
//do something...
}
optimize
//some declarations
...
//Load graph.
...
//According to the ops of loaded graph, optimize compute graph.
graph->Optimize();
save
//some declarations
...
//Load graph.
...
// save a model
//save_model_path: the path to where your model is.
auto status = graph->save(save_model_path);
//Checking
if(!status){
cout << "error" << endl;
//do somethin...
}
Net
Net是计算图的执行器,通过Net对象获得输入和输出。
template<typename TargetType, DataType Dtype, Precision PType, OpRunType RunType = OpRunType::ASYNC>
class Net{
//some implements
...
};
- Precision指定Op的精度。
- OpRunType表示同步或异步类型,异步是默认类型。OpRunType::SYNC表示同步,在GPU上只有单个流;OpRunType::ASYNC表示异步,在GPU上有多个流并以异步方式执行。
Precision
| Precision | Op support |
|---|---|
| Precision::INT4 | NO |
| Precision::INT8 | NO |
| Precision::FP16 | NO |
| Precision::FP32 | YES |
| Precision::FP64 | NO |
现在Op的精度只支持FP32, 但在将来我们会支持剩下的Precision.
OpRunType
| OpRunType | Sync/Aync | Description |
|---|---|---|
| OpRunType::SYNC | Synchronization | single-stream on GPU |
| OpRunType::ASYNC | Asynchronization | multi-stream on GPU |
create a executor
//some declarations
...
//Create a pointer to a graph.
auto graph = new Graph<NV, AK_FLOAT, Precision::FP32>();
//do something...
...
//create a executor
Net<NV, AK_FLOAT, Precision::FP32> executor(*graph);
get input tensor
//some declaratinos
...
//create a executor
//TargetType is NV [NVIDIA GPU]
Net<NV, AK_FLOAT, Precision::FP32> executor(*graph);
//Get the first input tensor.
//The following tensors(tensor_in0, tensor_in2 ...) are resident at GPU.
//Note: Member function get_in returns an pointer to tensor.
Tensor<NV, AK_FLOAT>* tensor_in0 = executor.get_in("input_0");
//If you have multiple input tensors
//You just type this code below.
Tensor<NV, AK_FLOAT>* tensor_in1 = executor.get_in("input_1");
...
auto tensor_inn = executor.get_in("input_n");
fill input tensor
//This tensor is resident at GPU.
auto tensor_d_in = executor.get_in("input_0");
//If we want to feed above tensor, we must feed the tensor which is resident at host. And then copy the host tensor to the device's one.
//using Tensor4d = Tensor<Ttype, Dtype>;
Tensor4d<X86, AK_FLOAT> tensor_h_in; //host tensor;
//Tensor<X86, AK_FLOAT> tensor_h_in;
//Allocate memory for host tensor.
tensor_h_in.re_alloc(tensor_d_in->valid_shape());
//Get a writable pointer to tensor.
float *h_data = tensor_h_in.mutable_data();
//Feed your tensor.
/** example
for(int i = 0; i < tensor_h_in.size(); i++){
h_data[i] = 1.0f;
}
*/
//Copy host tensor's data to device tensor.
tensor_d_in->copy_from(tensor_h_in);
// And then
get output tensor
//Note: this tensor are resident at GPU.
Tensor<NV, AK_FLOAT>* tensor_out_d = executor.get_out("pred_out");
execute graph
executor.prediction();
code example
1 | std::string model_path = "your_Anakin_models/xxxxx.anakin.bin"; |
anakin converter
1 | cd anakin/tools/external_converter_v2 |
config.yaml
1 | OPTIONS: |
- input: caffe.proto + lenet.prototxt + lenet_iter_10000.caffemodel
- output: output/mylenet.anakin.bin + log/xxx.log
anakin test
model_test.cpp
1 | cat Anakin/test/framework/net/model_test.cpp |
example_nv_cnn_net.cpp
1 | cat Anakin/examples/cuda/example_nv_cnn_net.cpp |
my example
my workspace
1 | ls demo/ |
anakin_lib
use ./tools/gpu_build.sh to generate gpu_build_sm61 and rename to anakin_lib
1 | ./tools/gpu_build.sh |
anakin-config.cmake
1 | set(ANAKIN_FOUND TRUE) # auto |
CMakeLists.txt
1 | cmake_minimum_required(VERSION 2.8.8) |
src/demo.cpp
edit from Anakin/examples/cuda/example_nv_cnn_net.cpp
1 |
|
compile demo
1 | mkdir build |
output
ERR| 16:45:56.00581| 110838.067s| 37CBF8C0| operator_attr.h:94] you have set the argument: is_reverse , so it's igrored by anakin
ERR| 16:45:56.00581| 110838.067s| 37CBF8C0| operator_attr.h:94] you have set the argument: is_reverse , so it's igrored by anakin
0| 16:45:56.00681| 0.098s| 37CBF8C0| parser.cpp:96] graph name: LeNet
0| 16:45:56.00681| 0.099s| 37CBF8C0| parser.cpp:101] graph in: input_0
0| 16:45:56.00681| 0.099s| 37CBF8C0| parser.cpp:107] graph out: prob_out
0| 16:45:56.00742| 0.159s| 37CBF8C0| graph.cpp:153] processing in-ordered fusion : ConvBatchnormScaleReluPool
0| 16:45:56.00742| 0.160s| 37CBF8C0| graph.cpp:153] processing in-ordered fusion : ConvBatchnormScaleRelu
0| 16:45:56.00742| 0.160s| 37CBF8C0| graph.cpp:153] processing in-ordered fusion : ConvReluPool
0| 16:45:56.00742| 0.160s| 37CBF8C0| graph.cpp:153] processing in-ordered fusion : ConvBatchnormScale
0| 16:45:56.00742| 0.160s| 37CBF8C0| graph.cpp:153] processing in-ordered fusion : DeconvRelu
0| 16:45:56.00742| 0.160s| 37CBF8C0| graph.cpp:153] processing in-ordered fusion : ConvRelu
0| 16:45:56.00742| 0.160s| 37CBF8C0| graph.cpp:153] processing in-ordered fusion : PermutePower
0| 16:45:56.00742| 0.160s| 37CBF8C0| graph.cpp:153] processing in-ordered fusion : ConvBatchnorm
0| 16:45:56.00742| 0.160s| 37CBF8C0| graph.cpp:153] processing in-ordered fusion : EltwiseRelu
0| 16:45:56.00742| 0.160s| 37CBF8C0| graph.cpp:153] processing in-ordered fusion : EltwiseActivation
WAN| 16:45:56.00743| 0.160s| 37CBF8C0| net.cpp:663] Detect and initial 1 lanes.
0| 16:45:56.00743| 0.161s| 37CBF8C0| env.h:44] found 1 device(s)
0| 16:45:56.00743| 0.161s| 37CBF8C0| cuda_device.cpp:45] Device id: 0 , name: GeForce GTX 1060
0| 16:45:56.00743| 0.161s| 37CBF8C0| cuda_device.cpp:47] Multiprocessors: 10
0| 16:45:56.00743| 0.161s| 37CBF8C0| cuda_device.cpp:50] frequency:1733MHz
0| 16:45:56.00743| 0.161s| 37CBF8C0| cuda_device.cpp:52] CUDA Capability : 6.1
0| 16:45:56.00743| 0.161s| 37CBF8C0| cuda_device.cpp:54] total global memory: 6078MBytes.
WAN| 16:45:56.00743| 0.161s| 37CBF8C0| net.cpp:667] Current used device id : 0
WAN| 16:45:56.00744| 0.161s| 37CBF8C0| input.cpp:16] Parsing Input op parameter.
0| 16:45:56.00744| 0.161s| 37CBF8C0| input.cpp:19] |-- shape [0]: 1
0| 16:45:56.00744| 0.161s| 37CBF8C0| input.cpp:19] |-- shape [1]: 1
0| 16:45:56.00744| 0.161s| 37CBF8C0| input.cpp:19] |-- shape [2]: 28
0| 16:45:56.00744| 0.161s| 37CBF8C0| input.cpp:19] |-- shape [3]: 28
ERR| 16:45:56.00744| 0.161s| 37CBF8C0| net.cpp:210] node_ptr->get_op_name() sass not support yet.
ERR| 16:45:56.00744| 0.161s| 37CBF8C0| net.cpp:210] node_ptr->get_op_name() sass not support yet.
WAN| 16:45:57.00269| 0.686s| 37CBF8C0| context.h:40] device index exceeds the number of devices, set to default device(0)!
0| 16:45:57.00270| 0.687s| 37CBF8C0| net.cpp:300] Temp mem used: 0 MB
0| 16:45:57.00270| 0.687s| 37CBF8C0| net.cpp:301] Original mem used: 0 MB
0| 16:45:57.00270| 0.687s| 37CBF8C0| net.cpp:302] Model mem used: 1 MB
0| 16:45:57.00270| 0.687s| 37CBF8C0| net.cpp:303] System mem used: 153 MB
0| 16:45:57.00270| 0.687s| 37CBF8C0| demo.cpp:40] height*width =784
0| 16:45:57.00270| 0.687s| 37CBF8C0| demo.cpp:41] h_tensor_in.size() =784
0| 16:45:57.00270| 0.688s| 37CBF8C0| demo.cpp:105] infer finish
0| 16:45:57.00270| 0.688s| 37CBF8C0| demo.cpp:117] out [0] = 0
0| 16:45:57.00270| 0.688s| 37CBF8C0| demo.cpp:117] out [1] = 0
0| 16:45:57.00270| 0.688s| 37CBF8C0| demo.cpp:117] out [2] = 0
0| 16:45:57.00270| 0.688s| 37CBF8C0| demo.cpp:117] out [3] = 1
0| 16:45:57.00270| 0.688s| 37CBF8C0| demo.cpp:117] out [4] = 0
0| 16:45:57.00270| 0.688s| 37CBF8C0| demo.cpp:117] out [5] = 0
0| 16:45:57.00270| 0.688s| 37CBF8C0| demo.cpp:117] out [6] = 0
0| 16:45:57.00270| 0.688s| 37CBF8C0| demo.cpp:117] out [7] = 0
0| 16:45:57.00270| 0.688s| 37CBF8C0| demo.cpp:117] out [8] = 0
0| 16:45:57.00270| 0.688s| 37CBF8C0| demo.cpp:117] out [9] = 0
For Windows (skip)
version
- windows 10
- vs 2015
- cmake 3.2.2
- cuda 8.0 + cudnn 6.0.21 (same as caffe) sm_61
- protobuf 3.4.0
protobuf
see compile protobuf-cpp on windows 10
compile
1 | #git clone https://github.com/PaddlePaddle/Anakin.git anakin |
with options
CUDNN_ROOT "C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v8.0/"
PROTOBUF_ROOT "C:/Program Files/protobuf"
BUILD_SHARED ON
USE_GPU_PLACE ON
USE_OPENMP OFF
USE_OPENCV ON
generate Anakin.sln and compile with VS 2015 with x64 Release mode.
error fixs
we get 101 errors, hard to fix.
skip now.
Reference
History
- 20180903: created.