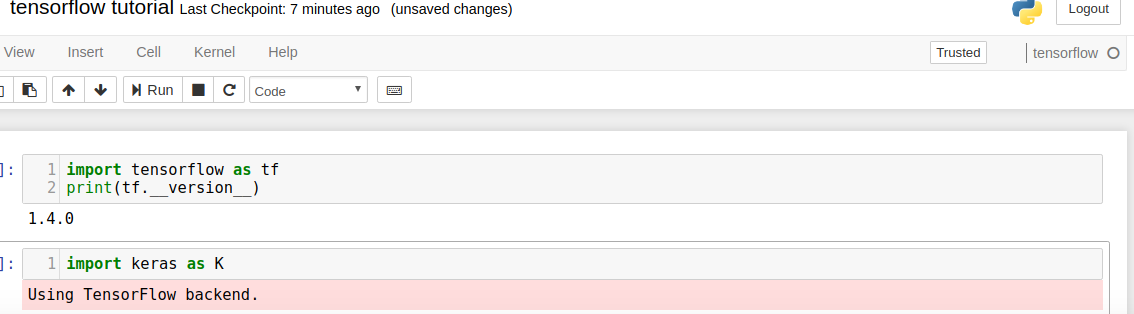
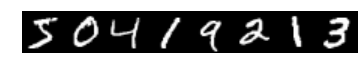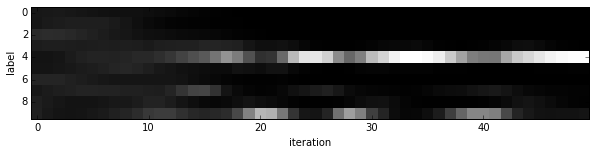ImportError: libcublas.so.9.0: cannot open shared object file: No such file or directory
ImportError: libcudnn.so.6: cannot open shared object file: No such file or directory
tensorflow-gpu 1.5 use cuda 9.0, so we install tensorflow-gpu 1.4to use cuda 8.0
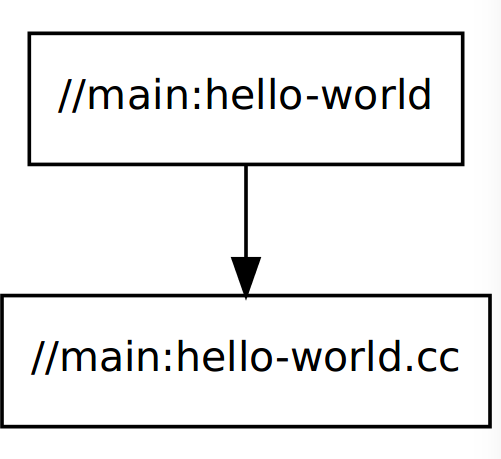
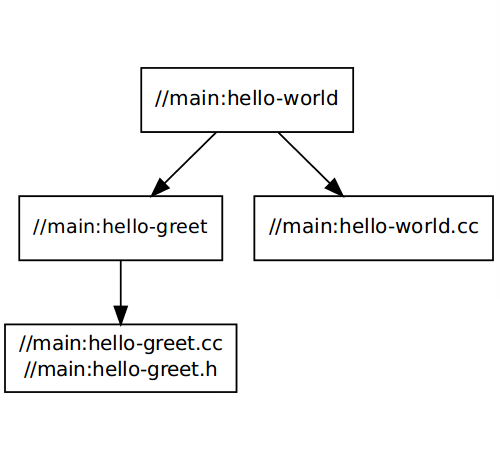
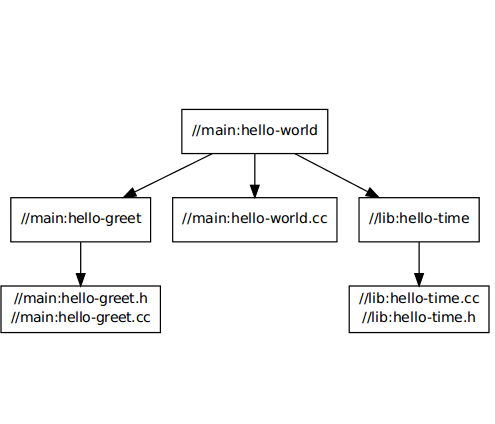
Bazel is an open-source build and test tool similar to Make, Maven, and Gradle. It uses a human-readable, high-level build language. Bazel supports projects in multiple languages and builds outputs for multiple platforms. Bazel supports large codebases across multiple repositories, and large numbers of users.
support language and platform:
c++
java
android
ios
Using binary installer
1 2 3 4 5 6 7 8 9 10
sudo apt-get install pkg-config zip g++ zlib1g-dev unzip python
#download `bazel-0.16.1-installer-linux-x86_64.sh` from `https://github.com/bazelbuild/bazel/releases`
chmod +x bazel-0.16.1-installer-linux-x86_64.sh ./bazel-0.16.1-installer-linux-x86_64.sh --user # The --user flag installs Bazel to the $HOME/bin directory on your system and sets the .bazelrc path to $HOME/.bazelrc.
# Make sure to clone with --recursive git clone --recursive https://github.com/rbgirshick/py-faster-rcnn.git
# Build the Cython modules py-faster-rcnn/lib make
# Build Caffe and pycaffe cd py-faster-rcnn/caffe-fast-rcnn mkdir build && cd build && cmake-gui .. make -j8
#Download pre-computed Faster R-CNN detectors
cd py-faster-rcnn ./data/scripts/fetch_faster_rcnn_models.sh
# This will populate the `FRCN_ROOT/data` folder with faster_rcnn_models. See `data/README.md` for details. These models were trained on VOC 2007 trainval.
# prepare data wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar
tar xvf VOCtrainval_06-Nov-2007.tar tar xvf VOCtest_06-Nov-2007.tar tar xvf VOCdevkit_08-Jun-2007.tar
VOCdevkit/ # development kit VOCdevkit/VOCcode/ # VOC utility code VOCdevkit/VOC2007 # image sets, annotations, etc. # ... and several other directories ...
cd py-faster-rcnn/data ln -s VOCdevkit VOCdevkit2007 # Using symlinks is a good idea because you will likely want to share the same PASCAL dataset installation between multiple projects.
# train net ./experiments/scripts/faster_rcnn_end2end.sh 0 ZF pascal_voc
error fixs
error
AttributeError: 'module' object has no attribute 'text_format'
fix
./lib/fast_rcnn/train.py增加一行
import google.protobuf.text_format
training results
AP for aeroplane = 0.6312
AP for bicycle = 0.7069
AP for bird = 0.5836
AP for boat = 0.4471
AP for bottle = 0.3562
AP for bus = 0.6682
AP for car = 0.7569
AP for cat = 0.7249
AP for chair = 0.3844
AP for cow = 0.6152
AP for diningtable = 0.6162
AP for dog = 0.6502
AP for horse = 0.7580
AP for motorbike = 0.7128
AP for person = 0.6744
AP for pottedplant = 0.3358
AP for sheep = 0.5872
AP for sofa = 0.5649
AP for train = 0.7128
AP for tvmonitor = 0.6133
Mean AP = 0.6050
Results:
0.631
0.707
0.584
0.447
0.356
0.668
0.757
0.725
0.384
0.615
0.616
0.650
0.758
0.713
0.674
0.336
0.587
0.565
0.713
0.613
0.605
--------------------------------------------------------------
Results computed with the **unofficial** Python eval code.
Results should be very close to the official MATLAB eval code.
Recompute with `./tools/reval.py --matlab ...` for your paper.
-- Thanks, The Management
--------------------------------------------------------------
real 5m16.906s
user 4m6.179s
sys 1m16.157s
The colors of our image are clearly wrong! Why is this?
The answer lies as a caveat with OpenCV.OpenCV represents RGB images as multi-dimensional NumPy arrays…but in reverse order! This means that OpenCV images are actually represented in BGR order rather than RGB!
1 2 3 4 5 6 7
import cv2 image = cv2.imread("images/cat.jpg") # convert from BGR to RGB rgb_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) plt.axis("off") plt.imshow(rgb_image) plt.show()
import sys caffe_root = '../'# this file should be run from {caffe_root}/examples (otherwise change this line) sys.path.insert(0, caffe_root + 'python')
keep in mind that the Transformer is only required when using a deploy.prototxt-like network definition, so without the Data Layer. When using a Data Layer, things get easier to understand.
import numpy as np import matplotlib.pyplot as plt
import sys caffe_root = '../'# this file should be run from {caffe_root}/examples (otherwise change this line) sys.path.insert(0, caffe_root + 'python')
transformer.set_transpose('data', (2,0,1)) # h,w,c->c,h,w(012->201) move image channels to outermost dimension transformer.set_channel_swap('data', (2,1,0)) # swap channels from RGB to BGR transformer.set_raw_scale('data', 255) # rescale from [0, 1] to [0, 255] transformer.set_mean('data', mu) # subtract the dataset-mean value(BGR) in each channel
# By default, using CaffeNet, your net.blobs['data'].data.shape == (10, 3, 227, 227). # This is because 10 random 227x227 crops are supposed to be extracted from a 256x256 image # and passed through the net.
# net.blobs['data'].reshape(50,3,227,227) # we can change network input mini-batch to 50 as we like # net.blobs['data'].data[...] = transformed_image # --->(50,3,227,227) 50 images
# By default, using CaffeNet, your net.blobs['data'].data.shape == (10, 3, 227, 227). # This is because 10 random 227x227 crops are supposed to be extracted from a 256x256 image # and passed through the net.
# net.blobs['data'].reshape(50,3,227,227) # we can change network input mini-batch to 50 as we like # net.blobs['data'].data[...] = transformed_image # --->(50,3,227,227) 50
import os import sys import cv2 import numpy as np # Make sure that caffe is on the python path: caffe_root = './' os.chdir(caffe_root) sys.path.insert(0, os.path.join(caffe_root, 'python')) import caffe
R-CNN is a state-of-the-art detector that classifies region proposals by a finetuned Caffe model. For the full details of the R-CNN system and model, refer to its project site and the paper:
Rich feature hierarchies for accurate object detection and semantic segmentation. Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik. CVPR 2014. Arxiv 2013.
In this example, we do detection by a pure Caffe edition of the R-CNN model for ImageNet. The R-CNN detector outputs class scores for the 200 detection classes of ILSVRC13. Keep in mind that these are raw one vs. all SVM scores, so they are not probabilistically calibrated or exactly comparable across classes. Note that this off-the-shelf model is simply for convenience, and is not the full R-CNN model.
Let’s run detection on an image of a bicyclist riding a fish bike in the desert (from the ImageNet challenge—no joke).
selective search
First, we’ll need region proposals and the Caffe R-CNN ImageNet model:
With that done, we’ll call the bundled detect.py to generate the region proposals and run the network. For an explanation of the arguments, do ./detect.py --help.
...
I1129 15:02:22.498908 3483 net.cpp:242] This network produces output fc-rcnn
I1129 15:02:22.498919 3483 net.cpp:255] Network initialization done.
I1129 15:02:22.577332 3483 upgrade_proto.cpp:53] Attempting to upgrade input file specified using deprecated V1LayerParameter: ../models/bvlc_reference_rcnn_ilsvrc13/bvlc_reference_rcnn_ilsvrc13.caffemodel
I1129 15:02:22.685262 3483 upgrade_proto.cpp:61] Successfully upgraded file specified using deprecated V1LayerParameter
I1129 15:02:22.685796 3483 upgrade_proto.cpp:67] Attempting to upgrade input file specified using deprecated input fields: ../models/bvlc_reference_rcnn_ilsvrc13/bvlc_reference_rcnn_ilsvrc13.caffemodel
I1129 15:02:22.685804 3483 upgrade_proto.cpp:70] Successfully upgraded file specified using deprecated input fields.
W1129 15:02:22.685809 3483 upgrade_proto.cpp:72] Note that future Caffe releases will only support input layers and not input fields.
Loading input...
selective_search_rcnn({'/home/kezunlin/program/caffe/examples/images/fish-bike.jpg'}, '/tmp/tmpkOe6J0.mat')
/home/kezunlin/program/caffe/python/caffe/detector.py:140: VisibleDeprecationWarning: using a non-integer number instead of an integer will result in an error in the future
crop = im[window[0]:window[2], window[1]:window[3]]
/home/kezunlin/program/caffe/python/caffe/detector.py:174: VisibleDeprecationWarning: using a non-integer number instead of an integer will result in an error in the future
context_crop = im[box[0]:box[2], box[1]:box[3]]
/usr/local/lib/python2.7/dist-packages/skimage/transform/_warps.py:84: UserWarning: The default mode, 'constant', will be changed to 'reflect' in skimage 0.15.
warn("The default mode, 'constant', will be changed to 'reflect' in "
/home/kezunlin/program/caffe/python/caffe/detector.py:177: VisibleDeprecationWarning: using a non-integer number instead of an integer will result in an error in the future
crop[pad_y:(pad_y + crop_h), pad_x:(pad_x + crop_w)] = context_crop
Processed 1565 windows in 15.899 s.
/usr/local/lib/python2.7/dist-packages/pandas/core/generic.py:1299: PerformanceWarning:
your performance may suffer as PyTables will pickle object types that it cannot
map directly to c-types [inferred_type->mixed,key->block1_values] [items->['prediction']]
return pytables.to_hdf(path_or_buf, key, self, **kwargs)
Saved to _temp/det_output.h5 in 0.082 s.
This run was in GPU mode. For CPU mode detection, call detect.py without the --gpu argument.
process regions
Running this outputs a DataFrame with the filenames, selected windows, and their detection scores to an HDF5 file. (We only ran on one image, so the filenames will all be the same.)
1 2 3 4 5 6 7 8 9 10 11 12
import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline
1570 regions were proposed with the R-CNN configuration of selective search. The number of proposals will vary from image to image based on its contents and size – selective search isn’t scale invariant.
In general, detect.py is most efficient when running on a lot of images: it first extracts window proposals for all of them, batches the windows for efficient GPU processing, and then outputs the results. Simply list an image per line in the images_file, and it will process all of them.
Although this guide gives an example of R-CNN ImageNet detection, detect.py is clever enough to adapt to different Caffe models’ input dimensions, batch size, and output categories. You can switch the model definition and pretrained model as desired. Refer to python detect.py --help for the parameters to describe your data set. There’s no need for hardcoding.
Anyway, let’s now load the ILSVRC13 detection class names and make a DataFrame of the predictions. Note you’ll need the auxiliary ilsvrc2012 data fetched by data/ilsvrc12/get_ilsvrc12_aux.sh.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline
#n01443537 goldfish #n03445777 golf ball #... withopen('../data/ilsvrc12/det_synset_words.txt') as f: # 200 classes from 1000 imagenet classes labels_df = pd.DataFrame([ { 'synset_id': l.strip().split(' ')[0], 'name': ' '.join(l.strip().split(' ')[1:]).split(',')[0] } for l in f.readlines() ]) labels_df.sort_values(by='synset_id') # from a... to z print labels_df.shape # (200, 2) print labels_df.head(5)
(200, 2)
name synset_id
0 accordion n02672831
1 airplane n02691156
2 ant n02219486
3 antelope n02419796
4 apple n07739125
name
person 1.839882
bicycle 0.855625
unicycle 0.085192
motorcycle 0.003604
turtle -0.030388
banjo -0.114999
electric fan -0.220595
cart -0.225192
lizard -0.365949
helmet -0.477555
dtype: float32
The top detections are in fact a person and bicycle. Picking good localizations is a work in progress; we pick the top-scoring person and bicycle detections.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
i = predictions_df['person'].argmax() # 70 rect j = predictions_df['bicycle'].argmax()# 262 rect
# Show top predictions for top detection. f = pd.Series(df['prediction'].iloc[i], index=labels_df['name']) # (200,) #print f.head(5) #print print('Top detection:') print(f.sort_values(ascending=False)[:5]) print('')
# Show top predictions for second-best detection. f = pd.Series(df['prediction'].iloc[j], index=labels_df['name']) # (200,) print('Second-best detection:') print(f.sort_values(ascending=False)[:5])
Top detection:
name
person 1.839882
swimming trunks -1.157806
turtle -1.168884
tie -1.217267
rubber eraser -1.246662
dtype: float32
Second-best detection:
name
bicycle 0.855625
unicycle -0.334367
scorpion -0.824552
lobster -0.965544
lamp -1.076224
dtype: float32
# Find, print, and display the top detections: person and bicycle. i = predictions_df['person'].argmax() j = predictions_df['bicycle'].argmax()
# Show top predictions for top detection. f = pd.Series(df['prediction'].iloc[i], index=labels_df['name']) print('Top detection:') print(f.sort_values(ascending=False)[:5]) print('')
# Show top predictions for second-best detection. f = pd.Series(df['prediction'].iloc[j], index=labels_df['name']) print('Second-best detection:') print(f.sort_values(ascending=False)[:5])
# Show top detection in red, second-best top detection in blue. im = plt.imread('images/fish-bike.jpg') plt.imshow(im) currentAxis = plt.gca()
defnms_detections(dets, overlap=0.3): """ Non-maximum suppression: Greedily select high-scoring detections and skip detections that are significantly covered by a previously selected detection. This version is translated from Matlab code by Tomasz Malisiewicz, who sped up Pedro Felzenszwalb's code. Parameters ---------- dets: ndarray each row is ['xmin', 'ymin', 'xmax', 'ymax', 'score'] overlap: float minimum overlap ratio (0.3 default) >iou,then drop rect Output ------ dets: ndarray remaining after suppression. """ x1 = dets[:, 0] y1 = dets[:, 1] x2 = dets[:, 2] y2 = dets[:, 3] ind = np.argsort(dets[:, 4]) # current ind set (min--->max)
w = x2 - x1 h = y2 - y1 area = (w * h).astype(float) """ dets pick = [] ind = [a,b,c,d,e,f] while not ind.empty: f, pick=[f], ind=[a,b,c,d,e], o=[0.1,0.2,0.5,0.9,0.2],keep_ind=[0,1,4],ind=[a,b,e] e, pick=[f,e], ind=[a,b], o=[0.4,0.1],keep_ind=[1],ind=[b] b, pick=[f,e,b],ind=[], o=[], keep_ind=[], ind=[] return dets[pick] """
pick = [] # pick index whilelen(ind) > 0: i = ind[-1] # choose last best index pick.append(i) ind = ind[:-1] # remove last one
This was an easy instance for bicycle as it was in the class’s training set. However, the person result is a true detection since this was not in the set for that class.
You should try out detection on an image of your own next!
(Remove the temp directory to clean up, and we’re done.)
In this tutorial we will do multilabel classification on PASCAL VOC 2012.
Multilabel classification is a generalization of multiclass classification, where each instance (image) can belong to many classes. For example, an image may both belong to a “beach” category and a “vacation pictures” category. In multiclass classification, on the other hand, each image belongs to a single class.
Caffe supports multilabel classification through the SigmoidCrossEntropyLoss layer, and we will load data using a Python data layer. Data could also be provided through HDF5 or LMDB data layers, but the python data layer provides endless flexibility, so that’s what we will use.
Preliminaries
First, make sure you compile caffe using WITH_PYTHON_LAYER := 1
Second, download PASCAL VOC 2012. It’s available here:
caffe_root = '../'# this file is expected to be in {caffe_root}/examples sys.path.append(caffe_root + 'python') import caffe # If you get "No module named _caffe", either you have not built pycaffe or you have the wrong path.
from caffe import layers as L, params as P # Shortcuts to define the net prototxt.
sys.path.append("pycaffe/layers") # the datalayers we will use are in this directory. sys.path.append("pycaffe") # the tools file is in this folder
import tools #this contains some tools that we need
Fourth, set data directories and initialize caffe
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
# set data root directory, e.g: pascal_root = osp.join(caffe_root, 'data/pascal/VOC2012')
# these are the PASCAL classes, we'll need them later. classes = np.asarray(['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'])
# make sure we have the caffenet weight downloaded. #if not os.path.isfile(caffe_root + 'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel'): # print("Downloading pre-trained CaffeNet model...") # !../scripts/download_model_binary.py ../models/bvlc_reference_caffenet
# initialize caffe for gpu mode caffe.set_mode_gpu() caffe.set_device(0)
Define network prototxts
Let’s start by defining the nets using caffe.NetSpec. Note how we used the SigmoidCrossEntropyLoss layer. This is the right loss for multilabel classification. Also note how the data layer is defined.
# write train net. withopen(osp.join(workdir, 'trainnet.prototxt'), 'w') as f: # provide parameters to the data layer as a python dictionary. Easy as pie! data_layer_params = dict(batch_size = 128, im_shape = [227, 227], split = 'train', pascal_root = pascal_root) f.write(caffenet_multilabel(data_layer_params, 'PascalMultilabelDataLayerSync'))
transformer = tools.SimpleTransformer() # This is simply to add back the bias, re-shuffle the color channels to RGB, and so on... image_index = 0# First image in the batch. image = solver.net.blobs['data'].data[image_index, ...] print image.shape # (3, 227, 227) BGR [0,255] #print image[0,:10,:10]
NOTE: we are readin the image from the data layer, so the resolution is lower than the original PASCAL image.
Train a net
Let’s train the net. First, though, we need some way to measure the accuracy. Hamming distance is commonly used in multilabel problems. We also need a simple test loop. Let’s write that down.
Great, the accuracy is increasing, and it seems to converge rather quickly. It may seem strange that it starts off so high but it is because the ground truth is sparse. There are 20 classes in PASCAL, and usually only one or two is present. So predicting all zeros yields rather high accuracy. Let’s check to make sure.
Caffe networks can be transformed to your particular needs by editing the model parameters. The data, diffs, and parameters of a net are all exposed in pycaffe.
Roll up your sleeves for net surgery with pycaffe!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
import numpy as np import matplotlib.pyplot as plt %matplotlib inline
# Make sure that caffe is on the python path: caffe_root = '../'# this file is expected to be in {caffe_root}/examples import sys sys.path.insert(0, caffe_root + 'python')
To show how to load, manipulate, and save parameters we’ll design our own filters into a simple network that’s only a single convolution layer. This net has two blobs, data for the input and conv for the convolution output and one parameter conv for the convolution filter weights and biases.
# Load the net, list its data and params, and filter an example image. caffe.set_mode_cpu() net = caffe.Net('net_surgery/conv.prototxt', caffe.TEST) print("blobs {}\nparams {}".format(net.blobs.keys(), net.params.keys()))
# load image and prepare as a single input batch for Caffe im = np.array(caffe.io.load_image('images/cat_gray.jpg', color=False)).squeeze() # caffe.io.load_image: dims: (height,width,channels),order: RGB,range: [0,1] dtype: float32 #(360, 480, 1)-->(360, 480) #print im[:5,:5]
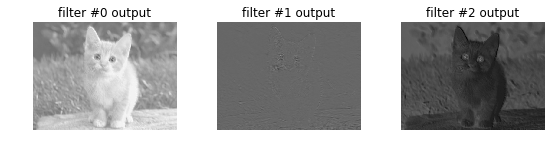
The convolution weights are initialized from Gaussian noise while the biases are initialized to zero. These random filters give output somewhat like edge detections.
Raising the bias of a filter will correspondingly raise its output:
1 2 3 4 5 6 7 8 9 10
# pick first filter output conv0 = net.blobs['conv'].data[0, 0] print("pre-surgery output mean {:.2f}".format(conv0.mean())) # set first filter bias to 1 #print net.params['conv'][1].data.shape net.params['conv'][1].data[0] = 1.#(3,) net.forward() print("post-surgery output mean {:.2f}".format(conv0.mean())) # for conv data,z = wx+b # z = wx+0, z = wx+1
pre-surgery output mean 0.04
(3,)
post-surgery output mean 1.04
Altering the filter weights is more exciting since we can assign any kernel like Gaussian blur, the Sobel operator for edges, and so on. The following surgery turns the 0th filter into a Gaussian blur and the 1st and 2nd filters into the horizontal and vertical gradient parts of the Sobel operator.
See how the 0th output is blurred, the 1st picks up horizontal edges, and the 2nd picks up vertical edges.
With net surgery, parameters can be transplanted across nets, regularized by custom per-parameter operations, and transformed according to your schemes.
Casting a Classifier into a Fully Convolutional Network
Let’s take the standard Caffe Reference ImageNet model “CaffeNet” and transform it into a fully convolutional net for efficient, dense inference on large inputs. This model generates a classification map that covers a given input size instead of a single classification. In particular a 8 $\times$ 8 classification map on a 451 $\times$ 451 input gives 64x the output in only 3x the time. The computation exploits a natural efficiency of convolutional network (convnet) structure by amortizing the computation of overlapping receptive fields.
To do so we translate the InnerProduct matrix multiplication layers of CaffeNet into Convolutional layers. This is the only change: the other layer types are agnostic to spatial size. Convolution is translation-invariant, activations are elementwise operations, and so on. The fc6 inner product when carried out as convolution by fc6-conv turns into a 6 $\times$ 6 filter with stride 1 on pool5. Back in image space this gives a classification for each 227 $\times$ 227 box with stride 32 in pixels. Remember the equation for output map / receptive field size, output = (input - kernel_size) / stride + 1, and work out the indexing details for a clear understanding.
The only differences needed in the architecture are to change the fully connected classifier inner product layers into convolutional layers with the right filter size – 6 x 6, since the reference model classifiers take the 36 elements of pool5 as input – and stride 1 for dense classification. Note that the layers are renamed so that Caffe does not try to blindly load the old parameters when it maps layer names to the pretrained model.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
# Load the original network and extract the fully connected layers' parameters. net = caffe.Net('../models/bvlc_reference_caffenet/deploy.prototxt', '../models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel', caffe.TEST) params = ['fc6', 'fc7', 'fc8'] # fc_params = {name: (weights, biases)} fc_params = {pr: (net.params[pr][0].data, net.params[pr][1].data) for pr in params}
for pr in params: print'{} weights are {} dimensional and biases are {} dimensional'.format(pr, fc_params[pr][0].shape, fc_params[pr][1].shape) pr = 'fc6' print net.params[pr][0].data[0,:6*6] # no weight_filler,loaded from weights file print net.params[pr][1].data[0] # no bias_filler,loaded from weights file
fc6 weights are (4096, 9216) dimensional and biases are (4096,) dimensional
fc7 weights are (4096, 4096) dimensional and biases are (4096,) dimensional
fc8 weights are (1000, 4096) dimensional and biases are (1000,) dimensional
[ 0.00639847 0.00915686 0.00467043 0.00118941 0.00083305 0.00249258
0.00249609 -0.00354958 -0.00502381 -0.00660044 -0.00810635 -0.00120969
-0.00182751 -0.00181385 -0.00327348 -0.00657627 -0.01059825 -0.00223066
0.00023664 0.00040984 -0.00052619 -0.00124062 -0.00269398 -0.00051081
0.0014997 0.00123309 -0.00013806 -0.00111619 0.00321043 0.00284487
0.00051387 -0.00087142 -0.00038937 -0.0008678 0.0049024 0.00155215]
0.983698
1 2
for layer_name, blob in net.blobs.iteritems(): print layer_name + '\t' + str(blob.data.shape)
Consider the shapes of the inner product parameters. The weight dimensions are the output and input sizes while the bias dimension is the output size.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
# Load the fully convolutional network to transplant the parameters. net_full_conv = caffe.Net('net_surgery/bvlc_caffenet_full_conv.prototxt', '../models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel', caffe.TEST) params_full_conv = ['fc6-conv', 'fc7-conv', 'fc8-conv'] # conv_params = {name: (weights, biases)} conv_params = {pr: (net_full_conv.params[pr][0].data, net_full_conv.params[pr][1].data) for pr in params_full_conv}
for pr in params_full_conv: print'{} weights are {} dimensional and biases are {} dimensional'.format(pr, conv_params[pr][0].shape, conv_params[pr][1].shape)
pr = 'fc6-conv' print net_full_conv.params[pr][0].data[0,0,:,:] # no weight_filler,default to 0s print net_full_conv.params[pr][1].data[0] # no bias_filler,default to 0s
fc6-conv weights are (4096, 256, 6, 6) dimensional and biases are (4096,) dimensional
fc7-conv weights are (4096, 4096, 1, 1) dimensional and biases are (4096,) dimensional
fc8-conv weights are (1000, 4096, 1, 1) dimensional and biases are (1000,) dimensional
[[ 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0.]]
0.0
1 2
for layer_name, blob in net_full_conv.blobs.iteritems(): print layer_name + '\t' + str(blob.data.shape)
The convolution weights are arranged in output $\times$ input $\times$ height $\times$ width dimensions. To map the inner product weights to convolution filters, we could roll the flat inner product vectors into channel $\times$ height $\times$ width filter matrices, but actually these are identical in memory (as row major arrays) so we can assign them directly.
The biases are identical to those of the inner product.
defprint_params(): for pr in params: print pr, fc_params[pr][0].shape, fc_params[pr][1].shape
for pr in params_full_conv: print pr, conv_params[pr][0].shape, conv_params[pr][1].shape pr = 'fc6-conv' print'params value for ',pr print net_full_conv.params[pr][0].data[0,0,:,:] print net_full_conv.params[pr][1].data[0]
print'*'*50 print'(1) before updated by fc' print'*'*50 print_params()
# set w6,w7,w8 of conv from fc w6,w7,w8 for pr, pr_conv inzip(params, params_full_conv): conv_params[pr_conv][0].flat = fc_params[pr][0].flat # flat unrolls the arrays conv_params[pr_conv][1][...] = fc_params[pr][1]
print_conv_params = True print_conv_params = False if print_conv_params: pr = 'fc6' print net.params[pr][0].data[0,:6*6] # no weight_filler,loaded from weights file print net.params[pr][1].data[0] # no bias_filler,loaded from weights file
print print'after init from fc' pr = 'fc6-conv' print net_full_conv.params[pr][0].data[0,0,:,:] # no weight_filler,default to 0s, here updated by fc print net_full_conv.params[pr][1].data[0] # no bias_filler,default to 0s , here updated by fc
print'*'*50 print'(2) after updated by fc' print'*'*50 print_params()
To conclude, let’s make a classification map from the example cat image and visualize the confidence of “tiger cat” as a probability heatmap. This gives an 8-by-8 prediction on overlapping regions of the 451 $\times$ 451 input.
# make classification map by forward and print prediction indices at each location out = net_full_conv.forward() prob = out['prob'][0] # (1, 1000, 8, 8)-->(1000, 8, 8) classification_map = out['prob'][0].argmax(axis=0) print classification_map # (8,8)
# show net input and confidence map (probability of the top prediction at each location) plt.subplot(1, 2, 1) plt.imshow(transformer.deprocess('data', net_full_conv.blobs['data'].data[0]))
plt.subplot(1, 2, 2) plt.imshow(out['prob'][0,281]) # correct class = 281 plt.colorbar()
The classifications include various cats – 282 = tiger cat, 281 = tabby, 283 = persian – and foxes and other mammals.
In this way the fully connected layers can be extracted as dense features across an image (see net_full_conv.blobs['fc6'].data for instance), which is perhaps more useful than the classification map itself.
Note that this model isn’t totally appropriate for sliding-window detection since it was trained for whole-image classification. Nevertheless it can work just fine. Sliding-window training and finetuning can be done by defining a sliding-window ground truth and loss such that a loss map is made for every location and solving as usual. (This is an exercise for the reader.)
A thank you to Rowland Depp for first suggesting this trick.
In this example, we’ll explore a common approach that is particularly useful in real-world applications: take a pre-trained Caffe network and fine-tune the parameters on your custom data.
The advantage of this approach is that, since pre-trained networks are learned on a large set of images, the intermediate layers capture the “semantics” of the general visual appearance. Think of it as a very powerful generic visual feature that you can treat as a black box. On top of that, only a relatively small amount of data is needed for good performance on the target task.
First, we will need to prepare the data. This involves the following parts: (1) Get the ImageNet ilsvrc pretrained model with the provided shell scripts. (2) Download a subset of the overall Flickr style dataset for this demo. (3) Compile the downloaded Flickr dataset into a database that Caffe can then consume.
# round and cast from float32 to uint8 image = np.round(image) image = np.require(image, dtype=np.uint8)
return image
Setup and dataset download
Download data required for this exercise.
get_ilsvrc_aux.sh to download the ImageNet data mean, labels, etc.
download_model_binary.py to download the pretrained reference model
finetune_flickr_style/assemble_data.py downloads the style training and testing data
We’ll download just a small subset of the full dataset for this exercise: just 2000 of the 80K images, from 5 of the 20 style categories. (To download the full dataset, set full_dataset = True in the cell below.)
# Download just a small subset of the data for this exercise. # (2000 of 80K images, 5 of 20 labels.) # To download the entire dataset, set `full_dataset = True`. full_dataset = False if full_dataset: NUM_STYLE_IMAGES = NUM_STYLE_LABELS = -1 else: NUM_STYLE_IMAGES = 2000 NUM_STYLE_LABELS = 5
# This downloads the ilsvrc auxiliary data (mean file, etc), # and a subset of 2000 images for the style recognition task. import os os.chdir(caffe_root) # run scripts from caffe root !data/ilsvrc12/get_ilsvrc_aux.sh !scripts/download_model_binary.py models/bvlc_reference_caffenet !python examples/finetune_flickr_style/assemble_data.py \ --workers=-1 --seed=1701 \ --images=$NUM_STYLE_IMAGES --label=$NUM_STYLE_LABELS # back to examples os.chdir('examples')
Downloading...
--2016-02-24 00:28:36-- http://dl.caffe.berkeleyvision.org/caffe_ilsvrc12.tar.gz
Resolving dl.caffe.berkeleyvision.org (dl.caffe.berkeleyvision.org)... 169.229.222.251
Connecting to dl.caffe.berkeleyvision.org (dl.caffe.berkeleyvision.org)|169.229.222.251|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 17858008 (17M) [application/octet-stream]
Saving to: ‘caffe_ilsvrc12.tar.gz’
100%[======================================>] 17,858,008 112MB/s in 0.2s
2016-02-24 00:28:36 (112 MB/s) - ‘caffe_ilsvrc12.tar.gz’ saved [17858008/17858008]
Unzipping...
Done.
Model already exists.
Downloading 2000 images with 7 workers...
Writing train/val for 1996 successfully downloaded images.
Define weights, the path to the ImageNet pretrained weights we just downloaded, and make sure it exists.
1 2 3
import os weights = os.path.join(caffe_root, 'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel') assert os.path.exists(weights)
Load the 1000 ImageNet labels from ilsvrc12/synset_words.txt, and the 5 style labels from finetune_flickr_style/style_names.txt.
We’ll start by defining caffenet, a function which initializes the CaffeNet architecture (a minor variant on AlexNet), taking arguments specifying the data and number of output classes.
defcaffenet(data, label=None, train=True, num_classes=1000, classifier_name='fc8', learn_all=False): """Returns a NetSpec specifying CaffeNet, following the original proto text specification (./models/bvlc_reference_caffenet/train_val.prototxt).""" n = caffe.NetSpec() n.data = data param = learned_param if learn_all else frozen_param n.conv1, n.relu1 = conv_relu(n.data, 11, 96, stride=4, param=param) n.pool1 = max_pool(n.relu1, 3, stride=2) n.norm1 = L.LRN(n.pool1, local_size=5, alpha=1e-4, beta=0.75) n.conv2, n.relu2 = conv_relu(n.norm1, 5, 256, pad=2, group=2, param=param) n.pool2 = max_pool(n.relu2, 3, stride=2) n.norm2 = L.LRN(n.pool2, local_size=5, alpha=1e-4, beta=0.75) n.conv3, n.relu3 = conv_relu(n.norm2, 3, 384, pad=1, param=param) n.conv4, n.relu4 = conv_relu(n.relu3, 3, 384, pad=1, group=2, param=param) n.conv5, n.relu5 = conv_relu(n.relu4, 3, 256, pad=1, group=2, param=param) n.pool5 = max_pool(n.relu5, 3, stride=2) n.fc6, n.relu6 = fc_relu(n.pool5, 4096, param=param) if train: n.drop6 = fc7input = L.Dropout(n.relu6, in_place=True) else: fc7input = n.relu6 n.fc7, n.relu7 = fc_relu(fc7input, 4096, param=param) if train: n.drop7 = fc8input = L.Dropout(n.relu7, in_place=True) else: fc8input = n.relu7 # always learn fc8 (param=learned_param) fc8 = L.InnerProduct(fc8input, num_output=num_classes, param=learned_param) # give fc8 the name specified by argument `classifier_name` n.__setattr__(classifier_name, fc8) ifnot train: n.probs = L.Softmax(fc8) if label isnotNone: n.label = label n.loss = L.SoftmaxWithLoss(fc8, n.label) n.acc = L.Accuracy(fc8, n.label) # write the net to a temporary file and return its filename with tempfile.NamedTemporaryFile(delete=False) as f: f.write(str(n.to_proto())) return f.name
Now, let’s create a CaffeNet that takes unlabeled “dummy data” as input, allowing us to set its input images externally and see what ImageNet classes it predicts.
Define a function style_net which calls caffenet on data from the Flickr style dataset.
The new network will also have the CaffeNet architecture, with differences in the input and output:
the input is the Flickr style data we downloaded, provided by an ImageData layer
the output is a distribution over 20 classes rather than the original 1000 ImageNet classes
the classification layer is renamed from fc8 to fc8_flickr to tell Caffe not to load the original classifier (fc8) weights from the ImageNet-pretrained model
Use the style_net function defined above to initialize untrained_style_net, a CaffeNet with input images from the style dataset and weights from the pretrained ImageNet model.
Call forward on untrained_style_net to get a batch of style training data.
Pick one of the style net training images from the batch of 50 (we’ll arbitrarily choose #8 here). Display it, then run it through imagenet_net, the ImageNet-pretrained network to view its top 5 predicted classes from the 1000 ImageNet classes.
Below we chose an image where the network’s predictions happen to be reasonable, as the image is of a beach, and “sandbar” and “seashore” both happen to be ImageNet-1000 categories. For other images, the predictions won’t be this good, sometimes due to the network actually failing to recognize the object(s) present in the image, but perhaps even more often due to the fact that not all images contain an object from the (somewhat arbitrarily chosen) 1000 ImageNet categories. Modify the batch_index variable by changing its default setting of 8 to another value from 0-49 (since the batch size is 50) to see predictions for other images in the batch. (To go beyond this batch of 50 images, first rerun the above cell to load a fresh batch of data into style_net.)
We can also look at untrained_style_net‘s predictions, but we won’t see anything interesting as its classifier hasn’t been trained yet.
In fact, since we zero-initialized the classifier (see caffenet definition – no weight_filler is passed to the final InnerProduct layer), the softmax inputs should be all zero and we should therefore see a predicted probability of 1/N for each label (for N labels). Since we set N = 5, we get a predicted probability of 20% for each class.
We can also verify that the activations in layer fc7 immediately before the classification layer are the same as (or very close to) those in the ImageNet-pretrained model, since both models are using the same pretrained weights in the conv1 through fc7 layers.
Delete untrained_style_net to save memory. (Hang on to imagenet_net as we’ll use it again later.)
1
del untrained_style_net
Training the style classifier
Now, we’ll define a function solver to create our Caffe solvers, which are used to train the network (learn its weights). In this function we’ll set values for various parameters used for learning, display, and “snapshotting” – see the inline comments for explanations of what they mean. You may want to play with some of the learning parameters to see if you can improve on the results here!
defsolver(train_net_path, test_net_path=None, base_lr=0.001): s = caffe_pb2.SolverParameter()
# Specify locations of the train and (maybe) test networks. s.train_net = train_net_path if test_net_path isnotNone: s.test_net.append(test_net_path) s.test_interval = 1000# Test after every 1000 training iterations. s.test_iter.append(100) # Test on 100 batches each time we test.
# The number of iterations over which to average the gradient. # Effectively boosts the training batch size by the given factor, without # affecting memory utilization. s.iter_size = 1 s.max_iter = 100000# # of times to update the net (training iterations) # Solve using the stochastic gradient descent (SGD) algorithm. # Other choices include 'Adam' and 'RMSProp'. s.type = 'SGD'
# Set the initial learning rate for SGD. s.base_lr = base_lr
# Set `lr_policy` to define how the learning rate changes during training. # Here, we 'step' the learning rate by multiplying it by a factor `gamma` # every `stepsize` iterations. s.lr_policy = 'step' s.gamma = 0.1 s.stepsize = 20000
# Set other SGD hyperparameters. Setting a non-zero `momentum` takes a # weighted average of the current gradient and previous gradients to make # learning more stable. L2 weight decay regularizes learning, to help prevent # the model from overfitting. s.momentum = 0.9 s.weight_decay = 5e-4
# Display the current training loss and accuracy every 1000 iterations. s.display = 1000
# Snapshots are files used to store networks we've trained. Here, we'll # snapshot every 10K iterations -- ten times during training. s.snapshot = 10000 s.snapshot_prefix = caffe_root + 'models/finetune_flickr_style/finetune_flickr_style' # Train on the GPU. Using the CPU to train large networks is very slow. s.solver_mode = caffe_pb2.SolverParameter.GPU # Write the solver to a temporary file and return its filename. with tempfile.NamedTemporaryFile(delete=False) as f: f.write(str(s)) return f.name
Now we’ll invoke the solver to train the style net’s classification layer.
For the record, if you want to train the network using only the command line tool, this is the command:
However, we will train using Python in this example.
We’ll first define run_solvers, a function that takes a list of solvers and steps each one in a round robin manner, recording the accuracy and loss values each iteration. At the end, the learned weights are saved to a file.
defrun_solvers(niter, solvers, disp_interval=10): """Run solvers for niter iterations, returning the loss and accuracy recorded each iteration. `solvers` is a list of (name, solver) tuples.""" blobs = ('loss', 'acc') loss, acc = ({name: np.zeros(niter) for name, _ in solvers} for _ in blobs) for it inrange(niter): for name, s in solvers: s.step(1) # run a single SGD step in Caffe loss[name][it], acc[name][it] = (s.net.blobs[b].data.copy() for b in blobs) if it % disp_interval == 0or it + 1 == niter: loss_disp = '; '.join('%s: loss=%.3f, acc=%2d%%' % (n, loss[n][it], np.round(100*acc[n][it])) for n, _ in solvers) print'%3d) %s' % (it, loss_disp) # Save the learned weights from both nets. weight_dir = tempfile.mkdtemp() weights = {} for name, s in solvers: filename = 'weights.%s.caffemodel' % name weights[name] = os.path.join(weight_dir, filename) s.net.save(weights[name]) return loss, acc, weights
Let’s create and run solvers to train nets for the style recognition task. We’ll create two solvers – one (style_solver) will have its train net initialized to the ImageNet-pretrained weights (this is done by the call to the copy_from method), and the other (scratch_style_solver) will start from a randomly initialized net.
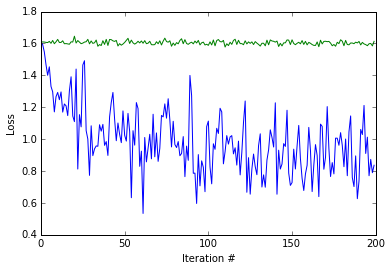
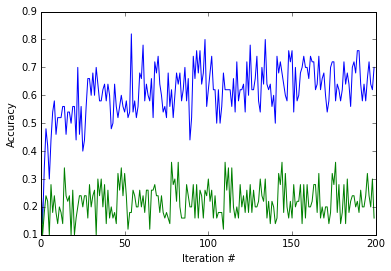
During training, we should see that the ImageNet pretrained net is learning faster and attaining better accuracies than the scratch net.
# For reference, we also create a solver that isn't initialized from # the pretrained ImageNet weights. scratch_style_solver_filename = solver(style_net(train=True)) scratch_style_solver = caffe.get_solver(scratch_style_solver_filename)
Let’s look at the training loss and accuracy produced by the two training procedures. Notice how quickly the ImageNet pretrained model’s loss value (blue) drops, and that the randomly initialized model’s loss value (green) barely (if at all) improves from training only the classifier layer.
Let’s take a look at the testing accuracy after running 200 iterations of training. Note that we’re classifying among 5 classes, giving chance accuracy of 20%. We expect both results to be better than chance accuracy (20%), and we further expect the result from training using the ImageNet pretraining initialization to be much better than the one from training from scratch. Let’s see.
1 2 3 4 5 6 7
defeval_style_net(weights, test_iters=10): test_net = caffe.Net(style_net(train=False), weights, caffe.TEST) accuracy = 0 for it in xrange(test_iters): accuracy += test_net.forward()['acc'] accuracy /= test_iters return test_net, accuracy
1 2 3 4
test_net, accuracy = eval_style_net(style_weights) print'Accuracy, trained from ImageNet initialization: %3.1f%%' % (100*accuracy, ) scratch_test_net, scratch_accuracy = eval_style_net(scratch_style_weights) print'Accuracy, trained from random initialization: %3.1f%%' % (100*scratch_accuracy, )
Accuracy, trained from ImageNet initialization: 50.0%
Accuracy, trained from random initialization: 23.6%
End-to-end finetuning for style
Finally, we’ll train both nets again, starting from the weights we just learned. The only difference this time is that we’ll be learning the weights “end-to-end” by turning on learning in all layers of the network, starting from the RGB conv1 filters directly applied to the input image. We pass the argument learn_all=True to the style_net function defined earlier in this notebook, which tells the function to apply a positive (non-zero) lr_mult value for all parameters. Under the default, learn_all=False, all parameters in the pretrained layers (conv1 through fc7) are frozen (lr_mult = 0), and we learn only the classifier layer fc8_flickr.
Note that both networks start at roughly the accuracy achieved at the end of the previous training session, and improve significantly with end-to-end training. To be more scientific, we’d also want to follow the same additional training procedure without the end-to-end training, to ensure that our results aren’t better simply because we trained for twice as long. Feel free to try this yourself!
# Set base_lr to 1e-3, the same as last time when learning only the classifier. # You may want to play around with different values of this or other # optimization parameters when fine-tuning. For example, if learning diverges # (e.g., the loss gets very large or goes to infinity/NaN), you should try # decreasing base_lr (e.g., to 1e-4, then 1e-5, etc., until you find a value # for which learning does not diverge). base_lr = 0.001
Let’s now test the end-to-end finetuned models. Since all layers have been optimized for the style recognition task at hand, we expect both nets to get better results than the ones above, which were achieved by nets with only their classifier layers trained for the style task (on top of either ImageNet pretrained or randomly initialized weights).
1 2 3 4
test_net, accuracy = eval_style_net(style_weights_ft) print'Accuracy, finetuned from ImageNet initialization: %3.1f%%' % (100*accuracy, ) scratch_test_net, scratch_accuracy = eval_style_net(scratch_style_weights_ft) print'Accuracy, finetuned from random initialization: %3.1f%%' % (100*scratch_accuracy, )
Accuracy, finetuned from ImageNet initialization: 53.6%
Accuracy, finetuned from random initialization: 39.2%
We’ll first look back at the image we started with and check our end-to-end trained model’s predictions.
We can also look at the predictions of the network trained from scratch. We see that in this case, the scratch network also predicts the correct label for the image (Pastel), but is much less confident in its prediction than the pretrained net.
So we did finetuning and it is awesome. Let’s take a look at what kind of results we are able to get with a longer, more complete run of the style recognition dataset. Note: the below URL might be occasionally down because it is run on a research machine.
We’ll be using the provided LeNet example data and networks (make sure you’ve downloaded the data and created the databases, as below).
1 2 3 4 5 6 7 8 9
# run scripts from caffe root import os os.chdir(caffe_root) # Download data !data/mnist/get_mnist.sh # Prepare data !examples/mnist/create_mnist.sh # back to examples os.chdir('examples')
Downloading...
Creating lmdb...
Done.
Creating the net
Now let’s make a variant of LeNet, the classic 1989 convnet architecture.
We’ll need two external files to help out:
the net prototxt, defining the architecture and pointing to the train/test data
the solver prototxt, defining the learning parameters
We start by creating the net. We’ll write the net in a succinct and natural way as Python code that serializes to Caffe’s protobuf model format.
This network expects to read from pregenerated LMDBs, but reading directly from ndarrays is also possible using MemoryDataLayer.
deflenet(lmdb, batch_size): # our version of LeNet: a series of linear and simple nonlinear transformations n = caffe.NetSpec() n.data, n.label = L.Data(batch_size=batch_size, backend=P.Data.LMDB, source=lmdb, transform_param=dict(scale=1./255), ntop=2) n.conv1 = L.Convolution(n.data, kernel_size=5, num_output=20, weight_filler=dict(type='xavier')) n.pool1 = L.Pooling(n.conv1, kernel_size=2, stride=2, pool=P.Pooling.MAX) n.conv2 = L.Convolution(n.pool1, kernel_size=5, num_output=50, weight_filler=dict(type='xavier')) n.pool2 = L.Pooling(n.conv2, kernel_size=2, stride=2, pool=P.Pooling.MAX) n.fc1 = L.InnerProduct(n.pool2, num_output=500, weight_filler=dict(type='xavier')) n.relu1 = L.ReLU(n.fc1, in_place=True) n.score = L.InnerProduct(n.relu1, num_output=10, weight_filler=dict(type='xavier')) n.loss = L.SoftmaxWithLoss(n.score, n.label) return n.to_proto() withopen('mnist/lenet_auto_train.prototxt', 'w') as f: f.write(str(lenet('mnist/mnist_train_lmdb', 64))) withopen('mnist/lenet_auto_test.prototxt', 'w') as f: f.write(str(lenet('mnist/mnist_test_lmdb', 100)))
The net has been written to disk in a more verbose but human-readable serialization format using Google’s protobuf library. You can read, write, and modify this description directly. Let’s take a look at the train net.
Now let’s see the learning parameters, which are also written as a prototxt file (already provided on disk). We’re using SGD with momentum, weight decay, and a specific learning rate schedule.
1
!cat mnist/lenet_auto_solver.prototxt
# The train/test net protocol buffer definition
train_net: "mnist/lenet_auto_train.prototxt"
test_net: "mnist/lenet_auto_test.prototxt"
# test_iter specifies how many forward passes the test should carry out.
# In the case of MNIST, we have test batch size 100 and 100 test iterations,
# covering the full 10,000 testing images.
test_iter: 100
# Carry out testing every 500 training iterations.
test_interval: 500
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005
# The learning rate policy
lr_policy: "inv"
gamma: 0.0001
power: 0.75
# Display every 100 iterations
display: 100
# The maximum number of iterations
max_iter: 10000
# snapshot intermediate results
snapshot: 5000
snapshot_prefix: "mnist/lenet"
Loading and checking the solver
Let’s pick a device and load the solver. We’ll use SGD (with momentum), but other methods (such as Adagrad and Nesterov’s accelerated gradient) are also available.
1 2 3 4 5 6
caffe.set_device(0) caffe.set_mode_gpu()
### load the solver and create train and test nets solver = None# ignore this workaround for lmdb data (can't instantiate two solvers on the same data) solver = caffe.SGDSolver('mnist/lenet_auto_solver.prototxt')
To get an idea of the architecture of our net, we can check the dimensions of the intermediate features (blobs) and parameters (these will also be useful to refer to when manipulating data later).
1 2
# each output is (batch size, feature dim, spatial dim) [(k, v.data.shape) for k, v in solver.net.blobs.items()]
Before taking off, let’s check that everything is loaded as we expect. We’ll run a forward pass on the train and test nets and check that they contain our data.
1 2
solver.net.forward() # train net solver.test_nets[0].forward() # test net (there can be more than one)
{'loss': array(2.365971088409424, dtype=float32)}
1 2 3
# we use a little trick to tile the first eight images imshow(solver.net.blobs['data'].data[:8, 0].transpose(1, 0, 2).reshape(28, 8*28), cmap='gray'); axis('off') print'train labels:', solver.net.blobs['label'].data[:8]
Both train and test nets seem to be loading data, and to have correct labels.
Let’s take one step of (minibatch) SGD and see what happens.
1
solver.step(1)
Do we have gradients propagating through our filters? Let’s see the updates to the first layer, shown here as a $4 \times 5$ grid of $5 \times 5$ filters.
Something is happening. Let’s run the net for a while, keeping track of a few things as it goes. Note that this process will be the same as if training through the caffe binary. In particular:
logging will continue to happen as normal
snapshots will be taken at the interval specified in the solver prototxt (here, every 5000 iterations)
testing will happen at the interval specified (here, every 500 iterations)
Since we have control of the loop in Python, we’re free to compute additional things as we go, as we show below. We can do many other things as well, for example:
write a custom stopping criterion
change the solving process by updating the net in the loop
%%time niter = 200 test_interval = 25 # losses will also be stored in the log train_loss = zeros(niter) test_acc = zeros(int(np.ceil(niter / test_interval))) output = zeros((niter, 8, 10))
# the main solver loop for it inrange(niter): solver.step(1) # SGD by Caffe # store the train loss train_loss[it] = solver.net.blobs['loss'].data # store the output on the first test batch # (start the forward pass at conv1 to avoid loading new data) solver.test_nets[0].forward(start='conv1') output[it] = solver.test_nets[0].blobs['score'].data[:8] # run a full test every so often # (Caffe can also do this for us and write to a log, but we show here # how to do it directly in Python, where more complicated things are easier.) if it % test_interval == 0: print'Iteration', it, 'testing...' correct = 0 for test_it inrange(100): solver.test_nets[0].forward() correct += sum(solver.test_nets[0].blobs['score'].data.argmax(1) == solver.test_nets[0].blobs['label'].data) test_acc[it // test_interval] = correct / 1e4
Iteration 0 testing...
Iteration 25 testing...
Iteration 50 testing...
Iteration 75 testing...
Iteration 100 testing...
Iteration 125 testing...
Iteration 150 testing...
Iteration 175 testing...
CPU times: user 12.6 s, sys: 2.4 s, total: 15 s
Wall time: 14.4 s
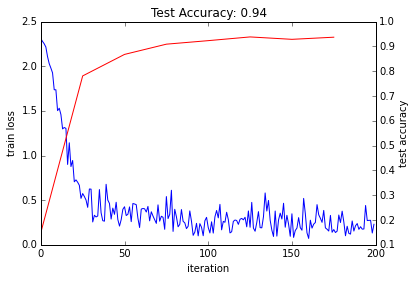
The loss seems to have dropped quickly and coverged (except for stochasticity), while the accuracy rose correspondingly. Hooray!
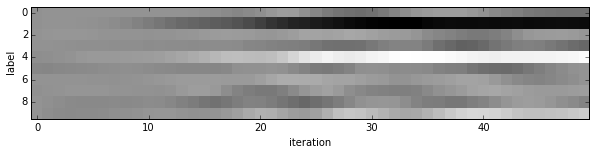
Since we saved the results on the first test batch, we can watch how our prediction scores evolved. We’ll plot time on the $x$ axis and each possible label on the $y$, with lightness indicating confidence.
1 2 3 4 5 6 7
for i inrange(8): figure(figsize=(2, 2)) imshow(solver.test_nets[0].blobs['data'].data[i, 0], cmap='gray') figure(figsize=(10, 2)) imshow(output[:50, i].T, interpolation='nearest', cmap='gray') xlabel('iteration') ylabel('label')
We started with little idea about any of these digits, and ended up with correct classifications for each. If you’ve been following along, you’ll see the last digit is the most difficult, a slanted “9” that’s (understandably) most confused with “4”.
Note that these are the “raw” output scores rather than the softmax-computed probability vectors. The latter, shown below, make it easier to see the confidence of our net (but harder to see the scores for less likely digits).
1 2 3 4 5 6 7
for i inrange(8): figure(figsize=(2, 2)) imshow(solver.test_nets[0].blobs['data'].data[i, 0], cmap='gray') figure(figsize=(10, 2)) imshow(exp(output[:50, i].T) / exp(output[:50, i].T).sum(0), interpolation='nearest', cmap='gray') xlabel('iteration') ylabel('label')
Experiment with architecture and optimization
Now that we’ve defined, trained, and tested LeNet there are many possible next steps:
Define new architectures for comparison
Tune optimization by setting base_lr and the like or simply training longer
Switching the solver type from SGD to an adaptive method like AdaDelta or Adam
Feel free to explore these directions by editing the all-in-one example that follows. Look for “EDIT HERE“ comments for suggested choice points.
By default this defines a simple linear classifier as a baseline.
In case your coffee hasn’t kicked in and you’d like inspiration, try out
Switch the nonlinearity from ReLU to ELU or a saturing nonlinearity like Sigmoid
Stack more fully connected and nonlinear layers
Search over learning rate 10x at a time (trying 0.1 and 0.001)
Switch the solver type to Adam (this adaptive solver type should be less sensitive to hyperparameters, but no guarantees…)
Solve for longer by setting niter higher (to 500 or 1,000 for instance) to better show training differences
### define net defcustom_net(lmdb, batch_size): # define your own net! n = caffe.NetSpec() # keep this data layer for all networks n.data, n.label = L.Data(batch_size=batch_size, backend=P.Data.LMDB, source=lmdb, transform_param=dict(scale=1./255), ntop=2) # EDIT HERE to try different networks # this single layer defines a simple linear classifier # (in particular this defines a multiway logistic regression) n.score = L.InnerProduct(n.data, num_output=10, weight_filler=dict(type='xavier')) # EDIT HERE this is the LeNet variant we have already tried # n.conv1 = L.Convolution(n.data, kernel_size=5, num_output=20, weight_filler=dict(type='xavier')) # n.pool1 = L.Pooling(n.conv1, kernel_size=2, stride=2, pool=P.Pooling.MAX) # n.conv2 = L.Convolution(n.pool1, kernel_size=5, num_output=50, weight_filler=dict(type='xavier')) # n.pool2 = L.Pooling(n.conv2, kernel_size=2, stride=2, pool=P.Pooling.MAX) # n.fc1 = L.InnerProduct(n.pool2, num_output=500, weight_filler=dict(type='xavier')) # EDIT HERE consider L.ELU or L.Sigmoid for the nonlinearity # n.relu1 = L.ReLU(n.fc1, in_place=True) # n.score = L.InnerProduct(n.fc1, num_output=10, weight_filler=dict(type='xavier')) # keep this loss layer for all networks n.loss = L.SoftmaxWithLoss(n.score, n.label) return n.to_proto()
withopen(train_net_path, 'w') as f: f.write(str(custom_net('mnist/mnist_train_lmdb', 64))) withopen(test_net_path, 'w') as f: f.write(str(custom_net('mnist/mnist_test_lmdb', 100)))
### define solver from caffe.proto import caffe_pb2 s = caffe_pb2.SolverParameter()
# Set a seed for reproducible experiments: # this controls for randomization in training. s.random_seed = 0xCAFFE
# Specify locations of the train and (maybe) test networks. s.train_net = train_net_path s.test_net.append(test_net_path) s.test_interval = 500# Test after every 500 training iterations. s.test_iter.append(100) # Test on 100 batches each time we test.
s.max_iter = 10000# no. of times to update the net (training iterations) # EDIT HERE to try different solvers # solver types include "SGD", "Adam", and "Nesterov" among others. s.type = "SGD"
# Set the initial learning rate for SGD. s.base_lr = 0.01# EDIT HERE to try different learning rates # Set momentum to accelerate learning by # taking weighted average of current and previous updates. s.momentum = 0.9 # Set weight decay to regularize and prevent overfitting s.weight_decay = 5e-4
# Set `lr_policy` to define how the learning rate changes during training. # This is the same policy as our default LeNet. s.lr_policy = 'inv' s.gamma = 0.0001 s.power = 0.75 # EDIT HERE to try the fixed rate (and compare with adaptive solvers) # `fixed` is the simplest policy that keeps the learning rate constant. # s.lr_policy = 'fixed'
# Display the current training loss and accuracy every 1000 iterations. s.display = 1000
# Snapshots are files used to store networks we've trained. # We'll snapshot every 5K iterations -- twice during training. s.snapshot = 5000 s.snapshot_prefix = 'mnist/custom_net'
# Train on the GPU s.solver_mode = caffe_pb2.SolverParameter.GPU
# Write the solver to a temporary file and return its filename. withopen(solver_config_path, 'w') as f: f.write(str(s))
### load the solver and create train and test nets solver = None# ignore this workaround for lmdb data (can't instantiate two solvers on the same data) solver = caffe.get_solver(solver_config_path)
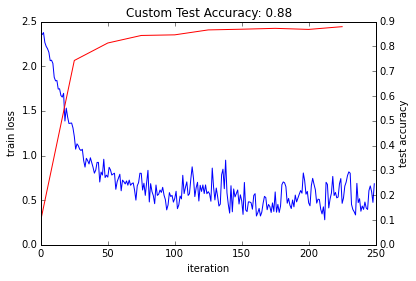
### solve niter = 250# EDIT HERE increase to train for longer test_interval = niter / 10 # losses will also be stored in the log train_loss = zeros(niter) test_acc = zeros(int(np.ceil(niter / test_interval)))
# the main solver loop for it inrange(niter): solver.step(1) # SGD by Caffe # store the train loss train_loss[it] = solver.net.blobs['loss'].data # run a full test every so often # (Caffe can also do this for us and write to a log, but we show here # how to do it directly in Python, where more complicated things are easier.) if it % test_interval == 0: print'Iteration', it, 'testing...' correct = 0 for test_it inrange(100): solver.test_nets[0].forward() correct += sum(solver.test_nets[0].blobs['score'].data.argmax(1) == solver.test_nets[0].blobs['label'].data) test_acc[it // test_interval] = correct / 1e4