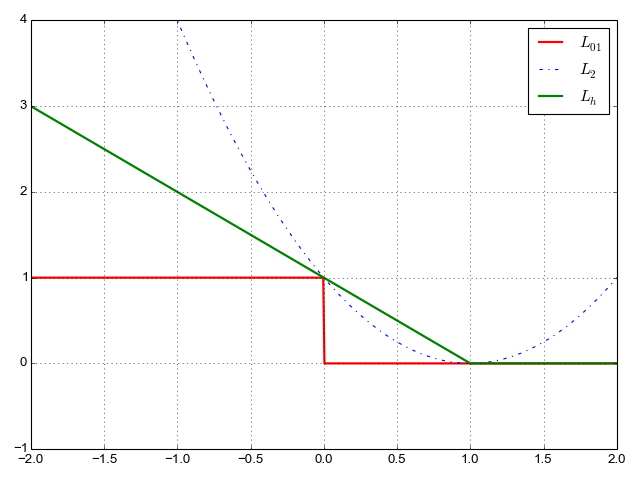
# Instantiate the base model (or "template" model). # We recommend doing this with under a CPU device scope, # so that the model's weights are hosted on CPU memory. # Otherwise they may end up hosted on a GPU, which would # complicate weight sharing. with tf.device('/cpu:0'): model = Xception(weights=None, input_shape=(height, width, 3), classes=num_classes)
# Replicates the model on 8 GPUs. # This assumes that your machine has 8 available GPUs. parallel_model = multi_gpu_model(model, gpus=G) parallel_model.compile(loss='categorical_crossentropy', optimizer='rmsprop')
# Generate dummy data. x = np.random.random((num_samples, height, width, 3)) y = np.random.random((num_samples, num_classes))
# This `fit` call will be distributed on 8 GPUs. # Since the batch size is 256, each GPU will process 32 samples. parallel_model.fit(x, y, epochs=20, batch_size=batch_size)
# Save model via the template model (which shares the same weights): model.save('my_model.h5')
Using a single GPU we were able to obtain 63 second epochs with a total training time of 74m10s. However, by using multi-GPU training with Keras and Python we decreased training time to 16 second epochs with a total training time of 19m3s. 4x times speedup!
for windows: drop files to MobaXterm to upload to server use zip format
commands
view disk
du -d 1 -h
df -h
gpu and cpu usage
watch -n 1 nvidia-smi
top
view files and count
wc -l data.csv
# count how many folders
ls -lR | grep '^d' | wc -l
17
# count how many jpg files
ls -lR | grep '.jpg' | wc -l
1360
# view 10 images
ls train | head
ls test | head
link datasets
# link
ln -s srt dest
ln -s /data_1/kezunlin/datasets/ dl4cv/datasets
wget -b -c http://developer.download.nvidia.com/compute/cuda/10.1/Prod/local_installers/cuda_10.1.243_418.87.00_linux.run
sudo sh cuda_10.1.243_418.87.00_linux.run
sudo ./cuda_10.1.243_418.87.00_linux.run
vim .bashrc
# for cuda and cudnn
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
kaggle config set --name competition --value dogs-vs-cats
- competition is now set to: dogs-vs-cats
kaggle config set --name competition --value dogs-vs-cats-redux-kernels-edition
dogs-vs-cats dogs-vs-cats-redux-kernels-edition
submit
kaggle c submissions
- Using competition: dogs-vs-cats
- No submissions found
kaggle c submit -f ./submission.csv -m "first submit"
if errors occur: Job for docker.service failed because the control process exited with error code. See “systemctl status docker.service” and “journalctl -xe” for details. check /etc/docker/daemon.json
test
sudo docker run --runtime=nvidia --rm nvidia/cuda:10.1-base nvidia-smi
sudo nvidia-docker run --rm nvidia/cuda:10.1-base nvidia-smi
Thu Aug 29 00:11:32 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 418.87.00 Driver Version: 418.87.00 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Quadro RTX 8000 Off | 00000000:02:00.0 Off | Off |
| 43% 67C P2 136W / 260W | 46629MiB / 48571MiB | 17% Default |
+-------------------------------+----------------------+----------------------+
| 1 Quadro RTX 8000 Off | 00000000:03:00.0 Off | Off |
| 34% 54C P0 74W / 260W | 0MiB / 48571MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 2 Quadro RTX 8000 Off | 00000000:82:00.0 Off | Off |
| 34% 49C P0 73W / 260W | 0MiB / 48571MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 3 Quadro RTX 8000 Off | 00000000:83:00.0 Off | Off |
| 33% 50C P0 73W / 260W | 0MiB / 48571MiB | 3% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
add user to docker group, and no need to use sudo docker xxx
# old version [NOT] # 0.4.1 pytorch/0.2.1 torchvision conda install pytorch=0.4.1 cuda90 -c pytorch
output
The following NEW packages will be INSTALLED:
pytorch pytorch/linux-64::pytorch-1.1.0-py3.5_cuda9.0.176_cudnn7.5.1_0
torchvision pytorch/linux-64::torchvision-0.3.0-py35_cu9.0.176_1
download from channel pytorch will cost much time! 下载pytorch/linux-64::pytorch-1.1.0-py3.5_cuda9.0.176_cudnn7.5.1_0速度非常慢!
# method 1 git clone --recursive https://github.com/pytorch/pytorch cd pytorch
# method 2, if you are updating an existing checkout git clone https://github.com/pytorch/pytorch cd pytorch git submodule sync git submodule update --init --recursive ``` check tags ```bash git tag -l
******** Summary ******** General: CMake version : 3.5.1 CMake command : /usr/bin/cmake System : Linux C++ compiler : /usr/bin/c++ C++ compiler id : GNU C++ compiler version : 5.4.0 BLAS : MKL CXX flags : -fvisibility-inlines-hidden -fopenmp -O2 -fPIC -Wno-narrowing -Wall -Wextra -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-sign-compare -Wno-unused-parameter -Wno-unused-variable -Wno-unused-function -Wno-unused-result -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math Build type : Release Compile definitions : ONNX_ML=1;ONNX_NAMESPACE=onnx_torch;USE_GCC_ATOMICS=1;HAVE_MMAP=1;_FILE_OFFSET_BITS=64;HAVE_SHM_OPEN=1;HAVE_SHM_UNLINK=1;HAVE_MALLOC_USABLE_SIZE=1 CMAKE_PREFIX_PATH : CMAKE_INSTALL_PREFIX : /usr/local
TORCH_VERSION : 1.1.0 CAFFE2_VERSION : 1.1.0 BUILD_CAFFE2_MOBILE : ON BUILD_ATEN_ONLY : OFF BUILD_BINARY : OFF BUILD_CUSTOM_PROTOBUF : ON Link local protobuf : ON BUILD_DOCS : OFF BUILD_PYTHON : OFF BUILD_CAFFE2_OPS : ON BUILD_SHARED_LIBS : ON BUILD_TEST : OFF INTERN_BUILD_MOBILE : USE_ASAN : OFF USE_CUDA : ON CUDA static link : OFF USE_CUDNN : ON CUDA version : 9.2 cuDNN version : 7.1.4 CUDA root directory : /usr/local/cuda CUDA library : /usr/local/cuda/lib64/stubs/libcuda.so cudart library : /usr/local/cuda/lib64/libcudart.so cublas library : /usr/local/cuda/lib64/libcublas.so cufft library : /usr/local/cuda/lib64/libcufft.so curand library : /usr/local/cuda/lib64/libcurand.so cuDNN library : /usr/local/cuda/lib64/libcudnn.so nvrtc : /usr/local/cuda/lib64/libnvrtc.so CUDA include path : /usr/local/cuda/include NVCC executable : /usr/local/cuda/bin/nvcc CUDA host compiler : /usr/bin/cc USE_TENSORRT : OFF USE_ROCM : OFF USE_EIGEN_FOR_BLAS : ON USE_FBGEMM : OFF USE_FFMPEG : OFF USE_GFLAGS : OFF USE_GLOG : OFF USE_LEVELDB : OFF USE_LITE_PROTO : OFF USE_LMDB : OFF USE_METAL : OFF USE_MKL : OFF USE_MKLDNN : OFF USE_NCCL : ON USE_SYSTEM_NCCL : OFF USE_NNPACK : ON USE_NUMPY : ON USE_OBSERVERS : ON USE_OPENCL : OFF USE_OPENCV : OFF USE_OPENMP : ON USE_TBB : OFF USE_PROF : OFF USE_QNNPACK : ON USE_REDIS : OFF USE_ROCKSDB : OFF USE_ZMQ : OFF USE_DISTRIBUTED : ON USE_MPI : ON USE_GLOO : ON USE_GLOO_IBVERBS : OFF NAMEDTENSOR_ENABLED : OFF Public Dependencies : Threads::Threads Private Dependencies : qnnpack;nnpack;cpuinfo;/usr/lib/x86_64-linux-gnu/libnuma.so;fp16;/usr/lib/openmpi/lib/libmpi_cxx.so;/usr/lib/openmpi/lib/libmpi.so;gloo;aten_op_header_gen;foxi_loader;rt;gcc_s;gcc;dl Configuring done
install pytorch
now compile and install
1 2
make -j8 sudo make install
output
Install the project...
-- Install configuration: "Release"
-- Old export file "/usr/local/share/cmake/Caffe2/Caffe2Targets.cmake" will be replaced. Removing files [/usr/local/share/cmake/Caffe2/Caffe2Targets-release.cmake].
-- Set runtime path of "/usr/local/bin/protoc" to "$ORIGIN"
-- Old export file "/usr/local/share/cmake/Gloo/GlooTargets.cmake" will be replaced. Removing files [/usr/local/share/cmake/Gloo/GlooTargets-release.cmake].
-- Set runtime path of "/usr/local/lib/libonnxifi_dummy.so" to "$ORIGIN"
-- Set runtime path of "/usr/local/lib/libonnxifi.so" to "$ORIGIN"
-- Set runtime path of "/usr/local/lib/libfoxi_dummy.so" to "$ORIGIN"
-- Set runtime path of "/usr/local/lib/libfoxi.so" to "$ORIGIN"
-- Set runtime path of "/usr/local/lib/libc10.so" to "$ORIGIN"
-- Set runtime path of "/usr/local/lib/libc10_cuda.so" to "$ORIGIN:/usr/local/cuda/lib64"
-- Set runtime path of "/usr/local/lib/libthnvrtc.so" to "$ORIGIN:/usr/local/cuda/lib64/stubs:/usr/local/cuda/lib64"
-- Set runtime path of "/usr/local/lib/libtorch.so" to "$ORIGIN:/usr/local/cuda/lib64:/usr/lib/openmpi/lib"
-- Set runtime path of "/usr/local/lib/libcaffe2_detectron_ops_gpu.so" to "$ORIGIN:/usr/local/cuda/lib64"
-- Set runtime path of "/usr/local/lib/libcaffe2_observers.so" to "$ORIGIN:/usr/local/cuda/lib64"
pytorch 1.1.0 compile and install will cost more than 2 hours lib install to /usr/local/lib/libtorch.so cmake install to /usr/local/share/cmake/Torch
@soumith You might be building libtorch with a compiler that is incompatible with the compiler building your final app. For example, you built libtorch with gcc 4.9.2 and your final app with gcc 5.1, and the C++ ABI between both of them is not the same, so you are seeing linker errors like these
if ("${CMAKE_CXX_COMPILER_ID}" STREQUAL "GNU")
set(TORCH_CXX_FLAGS "-D_GLIBCXX_USE_CXX11_ABI=0")
endif()
Which forces GCC to use the old C++11 ABI.
@ smth we have that flag set because we build with gcc 4.9.x, which only has the old ABI. In GCC 5.1, the ABI for std::string was changed, and binaries compiling with gcc >= 5.1 are not ABI-compatible with binaries build with gcc < 5.1 (like pytorch) unless you set that flag.
resons and solutions
Reasons: ** LibTorch compiled with GCC-4.9.X (only has the old ABI), and binaries compiling with gcc >= 5.1 are not ABI-compatible**
Solution: compile pytorch from source instead of using LibTroch downloaded from the website.
runtime errors with pytorch
errors
/usr/local/lib/libopencv_imgcodecs.so.3.1.0: undefined reference to `TIFFReadRGBAStrip@LIBTIFF_4.0'
It seems that my OpenCV was compiled against libtiff 4, but I have libtiff 5, how to solve this problem?
re-compile opencv-3.1.0 again, new errors occur see here
CMake Error: The following variables are used in this project, but they are set to NOTFOUND.
Please set them or make sure they are set and tested correctly in the CMake files:
CUDA_nppi_LIBRARY (ADVANCED)
linked by target "opencv_cudev" in directory /home/kezunlin/program/opencv-3.1.0/modules/cudev
linked by target "opencv_cudev" in directory /home/kezunlin/program/opencv-3.1.0/modules/cudev
linked by target "opencv_test_cudev" in directory /home/kezunlin/program/opencv-3.1.0/modules/cudev/test
solutions:
WITH_CUDA OFF
WITH_VTK OFF WITH_TIFF OFF BUILD_PERF_TESTS OFF
for python2, use default /usr/bin/python2.7 for python3, NOT USE anaconda version 编译的过程中,尽量避免使用anaconda目录下的lib
OpenCL is a framework for writing programs that execute on these heterogenous platforms. The developers of an OpenCL library utilize all OpenCL compatible devices (CPUs, GPUs, DSPs, FPGAs etc) they find on a computer / device and assign the right tasks to the right processor. Keep in mind that as a user of OpenCV library you are not developing any OpenCL library. In fact you are not even a user of the OpenCL library because all the details are hidden behind the transparent API/TAPI.
[/home/kezunlin/anaconda3] >>> PREFIX=/home/kezunlin/anaconda3 installing: python-3.7.3-h0371630_0 ... Python 3.7.3 ... installing: scikit-image-0.14.2-py37he6710b0_0 ... installing: scikit-learn-0.20.3-py37hd81dba3_0 ... installing: astropy-3.1.2-py37h7b6447c_0 ... installing: statsmodels-0.9.0-py37h035aef0_0 ... installing: seaborn-0.9.0-py37_0 ... installing: anaconda-2019.03-py37_0 ... installation finished. Do you wish the installer to initialize Anaconda3 by running conda init? [yes|no]
If you'd prefer that conda's base environment not be activated on startup, set the auto_activate_base parameter to false:
conda config --set auto_activate_base false
Thank you for installing Anaconda3!
conda config –set auto_activate_base false
check version
1 2 3 4 5 6 7
conda --version conda 4.6.11
conda update conda
conda --version conda 4.6.14
Managing Environments
create new env
When you begin using conda, you already have a default environment named base. You don’t want to put programs into your base environment, though. Create separate environments to keep your programs isolated from each other.
When you create a new environment, conda installs the same Python version you used when you downloaded and installed Anaconda. If you want to use a different version of Python, for example Python 3.5, simply create a new environment and specify the version of Python that you want.