Tutorial
Caffe networks can be transformed to your particular needs by editing the model parameters. The data, diffs, and parameters of a net are all exposed in pycaffe.
Roll up your sleeves for net surgery with pycaffe!
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# Make sure that caffe is on the python path:
caffe_root = '../' # this file is expected to be in {caffe_root}/examples
import sys
sys.path.insert(0, caffe_root + 'python')
import caffe
# configure plotting
plt.rcParams['figure.figsize'] = (10, 10)
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
Designer Filters
To show how to load, manipulate, and save parameters we’ll design our own filters into a simple network that’s only a single convolution layer. This net has two blobs, data for the input and conv for the convolution output and one parameter conv for the convolution filter weights and biases.
# Load the net, list its data and params, and filter an example image.
caffe.set_mode_cpu()
net = caffe.Net('net_surgery/conv.prototxt', caffe.TEST)
print("blobs {}\nparams {}".format(net.blobs.keys(), net.params.keys()))
# load image and prepare as a single input batch for Caffe
im = np.array(caffe.io.load_image('images/cat_gray.jpg', color=False)).squeeze()
# caffe.io.load_image: dims: (height,width,channels),order: RGB,range: [0,1] dtype: float32
#(360, 480, 1)-->(360, 480)
#print im[:5,:5]
plt.title("original image")
plt.imshow(im)
plt.axis('off')
im_input = im[np.newaxis, np.newaxis, :, :] #(1, 1, 360, 480) (c,h,w) [0,1] float32
net.blobs['data'].reshape(*im_input.shape) # (1, 1, 100, 100) --->(1, 1, 360, 480)
print net.blobs['data'].data.shape
net.blobs['data'].data[...] = im_input
blobs ['data', 'conv']
params ['conv']
[[ 0.10196079 0.10588235 0.09803922 0.10980392 0.11372549]
[ 0.10196079 0.10588235 0.09803922 0.10196079 0.10980392]
[ 0.10196079 0.10588235 0.10196079 0.10196079 0.10588235]
[ 0.10588235 0.10196079 0.10588235 0.10980392 0.11372549]
[ 0.11764706 0.10196079 0.10196079 0.10588235 0.10980392]]
(1, 1, 360, 480)

The convolution weights are initialized from Gaussian noise while the biases are initialized to zero. These random filters give output somewhat like edge detections.
# helper show filter outputs
def show_filters(net):
net.forward()
for name,blob in net.blobs.iteritems():
print name,blob.data.shape
# data (1, 1, 360, 480) o = (i+2*p-k)/s+1 ->360-5+1=356, 480-5+1=476
# conv (1, 3, 356, 476)
print
for name,param in net.params.iteritems():
print name,param[0].data.shape # conv (3, 1, 5, 5)
plt.figure()
filt_count = 3
filt_min, filt_max = net.blobs['conv'].data.min(), net.blobs['conv'].data.max()
print filt_min,filt_max
for i in range(3):
plt.subplot(1,4,i+2)
plt.title("filter #{} output".format(i))
plt.imshow(net.blobs['conv'].data[0, i], vmin=filt_min, vmax=filt_max)
#plt.imshow(net.blobs['conv'].data[0, i])
#cbar = plt.colorbar() # depends on vmin,vmax
plt.tight_layout()
plt.axis('off')
# filter the image with initial
show_filters(net)
data (1, 1, 360, 480)
conv (1, 3, 356, 476)
conv (3, 1, 5, 5)
-0.0651154 0.097207
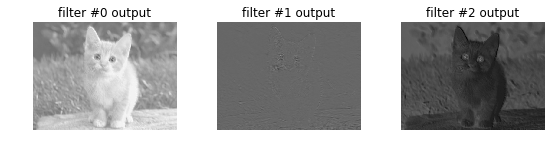
Raising the bias of a filter will correspondingly raise its output:
# pick first filter output
conv0 = net.blobs['conv'].data[0, 0]
print("pre-surgery output mean {:.2f}".format(conv0.mean()))
# set first filter bias to 1
#print net.params['conv'][1].data.shape
net.params['conv'][1].data[0] = 1. #(3,)
net.forward()
print("post-surgery output mean {:.2f}".format(conv0.mean()))
# for conv data,z = wx+b
# z = wx+0, z = wx+1
pre-surgery output mean 0.04
(3,)
post-surgery output mean 1.04
Altering the filter weights is more exciting since we can assign any kernel like Gaussian blur, the Sobel operator for edges, and so on. The following surgery turns the 0th filter into a Gaussian blur and the 1st and 2nd filters into the horizontal and vertical gradient parts of the Sobel operator.
See how the 0th output is blurred, the 1st picks up horizontal edges, and the 2nd picks up vertical edges.
ksize = net.params['conv'][0].data.shape[2:] # conv (3, 1, 5, 5)--->(5,5)
# make Gaussian blur
sigma = 1.
y, x = np.mgrid[-ksize[0]//2 + 1:ksize[0]//2 + 1, -ksize[1]//2 + 1:ksize[1]//2 + 1]
g = np.exp(-((x**2 + y**2)/(2.0*sigma**2)))
gaussian = (g / g.sum()).astype(np.float32)
net.params['conv'][0].data[0] = gaussian
# make Sobel operator for edge detection
net.params['conv'][0].data[1:] = 0.
sobel = np.array((-1, -2, -1, 0, 0, 0, 1, 2, 1), dtype=np.float32).reshape((3,3))
net.params['conv'][0].data[1, 0, 1:-1, 1:-1] = sobel # horizontal
net.params['conv'][0].data[2, 0, 1:-1, 1:-1] = sobel.T # vertical
show_filters(net)
data (1, 1, 360, 480)
conv (1, 3, 356, 476)
conv (3, 1, 5, 5)
-3.67843 3.77647

With net surgery, parameters can be transplanted across nets, regularized by custom per-parameter operations, and transformed according to your schemes.
Casting a Classifier into a Fully Convolutional Network
Let’s take the standard Caffe Reference ImageNet model “CaffeNet” and transform it into a fully convolutional net for efficient, dense inference on large inputs. This model generates a classification map that covers a given input size instead of a single classification. In particular a 8 $\times$ 8 classification map on a 451 $\times$ 451 input gives 64x the output in only 3x the time. The computation exploits a natural efficiency of convolutional network (convnet) structure by amortizing the computation of overlapping receptive fields.
To do so we translate the InnerProduct matrix multiplication layers of CaffeNet into Convolutional layers. This is the only change: the other layer types are agnostic to spatial size. Convolution is translation-invariant, activations are elementwise operations, and so on. The fc6 inner product when carried out as convolution by fc6-conv turns into a 6 $\times$ 6 filter with stride 1 on pool5. Back in image space this gives a classification for each 227 $\times$ 227 box with stride 32 in pixels. Remember the equation for output map / receptive field size, output = (input - kernel_size) / stride + 1, and work out the indexing details for a clear understanding.
!diff net_surgery/bvlc_caffenet_full_conv.prototxt ../models/bvlc_reference_caffenet/deploy.prototxt
1,2c1
< # Fully convolutional network version of CaffeNet.
< name: "CaffeNetConv"
---
> name: "CaffeNet"
7,11c6
< input_param {
< # initial shape for a fully convolutional network:
< # the shape can be set for each input by reshape.
< shape: { dim: 1 dim: 3 dim: 451 dim: 451 }
< }
---
> input_param { shape: { dim: 10 dim: 3 dim: 227 dim: 227 } }
157,158c152,153
< name: "fc6-conv"
< type: "Convolution"
---
> name: "fc6"
> type: "InnerProduct"
160,161c155,156
< top: "fc6-conv"
< convolution_param {
---
> top: "fc6"
> inner_product_param {
163d157
< kernel_size: 6
169,170c163,164
< bottom: "fc6-conv"
< top: "fc6-conv"
---
> bottom: "fc6"
> top: "fc6"
175,176c169,170
< bottom: "fc6-conv"
< top: "fc6-conv"
---
> bottom: "fc6"
> top: "fc6"
182,186c176,180
< name: "fc7-conv"
< type: "Convolution"
< bottom: "fc6-conv"
< top: "fc7-conv"
< convolution_param {
---
> name: "fc7"
> type: "InnerProduct"
> bottom: "fc6"
> top: "fc7"
> inner_product_param {
188d181
< kernel_size: 1
194,195c187,188
< bottom: "fc7-conv"
< top: "fc7-conv"
---
> bottom: "fc7"
> top: "fc7"
200,201c193,194
< bottom: "fc7-conv"
< top: "fc7-conv"
---
> bottom: "fc7"
> top: "fc7"
207,211c200,204
< name: "fc8-conv"
< type: "Convolution"
< bottom: "fc7-conv"
< top: "fc8-conv"
< convolution_param {
---
> name: "fc8"
> type: "InnerProduct"
> bottom: "fc7"
> top: "fc8"
> inner_product_param {
213d205
< kernel_size: 1
219c211
< bottom: "fc8-conv"
---
> bottom: "fc8"
The only differences needed in the architecture are to change the fully connected classifier inner product layers into convolutional layers with the right filter size – 6 x 6, since the reference model classifiers take the 36 elements of pool5 as input – and stride 1 for dense classification. Note that the layers are renamed so that Caffe does not try to blindly load the old parameters when it maps layer names to the pretrained model.
# Load the original network and extract the fully connected layers' parameters.
net = caffe.Net('../models/bvlc_reference_caffenet/deploy.prototxt',
'../models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel',
caffe.TEST)
params = ['fc6', 'fc7', 'fc8']
# fc_params = {name: (weights, biases)}
fc_params = {pr: (net.params[pr][0].data, net.params[pr][1].data) for pr in params}
for pr in params:
print '{} weights are {} dimensional and biases are {} dimensional'.format(pr, fc_params[pr][0].shape, fc_params[pr][1].shape)
pr = 'fc6'
print net.params[pr][0].data[0,:6*6] # no weight_filler,loaded from weights file
print net.params[pr][1].data[0] # no bias_filler,loaded from weights file
fc6 weights are (4096, 9216) dimensional and biases are (4096,) dimensional
fc7 weights are (4096, 4096) dimensional and biases are (4096,) dimensional
fc8 weights are (1000, 4096) dimensional and biases are (1000,) dimensional
[ 0.00639847 0.00915686 0.00467043 0.00118941 0.00083305 0.00249258
0.00249609 -0.00354958 -0.00502381 -0.00660044 -0.00810635 -0.00120969
-0.00182751 -0.00181385 -0.00327348 -0.00657627 -0.01059825 -0.00223066
0.00023664 0.00040984 -0.00052619 -0.00124062 -0.00269398 -0.00051081
0.0014997 0.00123309 -0.00013806 -0.00111619 0.00321043 0.00284487
0.00051387 -0.00087142 -0.00038937 -0.0008678 0.0049024 0.00155215]
0.983698
for layer_name, blob in net.blobs.iteritems():
print layer_name + '\t' + str(blob.data.shape)
data (10, 3, 227, 227)
conv1 (10, 96, 55, 55)
pool1 (10, 96, 27, 27)
norm1 (10, 96, 27, 27)
conv2 (10, 256, 27, 27)
pool2 (10, 256, 13, 13)
norm2 (10, 256, 13, 13)
conv3 (10, 384, 13, 13)
conv4 (10, 384, 13, 13)
conv5 (10, 256, 13, 13)
pool5 (10, 256, 6, 6)
fc6 (10, 4096)
fc7 (10, 4096)
fc8 (10, 1000)
prob (10, 1000)
for layer_name, param in net.params.iteritems():
print layer_name + '\t' + str(param[0].data.shape), str(param[1].data.shape)
conv1 (96, 3, 11, 11) (96,)
conv2 (256, 48, 5, 5) (256,)
conv3 (384, 256, 3, 3) (384,)
conv4 (384, 192, 3, 3) (384,)
conv5 (256, 192, 3, 3) (256,)
fc6 (4096, 9216) (4096,)
fc7 (4096, 4096) (4096,)
fc8 (1000, 4096) (1000,)
Consider the shapes of the inner product parameters. The weight dimensions are the output and input sizes while the bias dimension is the output size.
# Load the fully convolutional network to transplant the parameters.
net_full_conv = caffe.Net('net_surgery/bvlc_caffenet_full_conv.prototxt',
'../models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel',
caffe.TEST)
params_full_conv = ['fc6-conv', 'fc7-conv', 'fc8-conv']
# conv_params = {name: (weights, biases)}
conv_params = {pr: (net_full_conv.params[pr][0].data, net_full_conv.params[pr][1].data) for pr in params_full_conv}
for pr in params_full_conv:
print '{} weights are {} dimensional and biases are {} dimensional'.format(pr, conv_params[pr][0].shape, conv_params[pr][1].shape)
pr = 'fc6-conv'
print net_full_conv.params[pr][0].data[0,0,:,:] # no weight_filler,default to 0s
print net_full_conv.params[pr][1].data[0] # no bias_filler,default to 0s
fc6-conv weights are (4096, 256, 6, 6) dimensional and biases are (4096,) dimensional
fc7-conv weights are (4096, 4096, 1, 1) dimensional and biases are (4096,) dimensional
fc8-conv weights are (1000, 4096, 1, 1) dimensional and biases are (1000,) dimensional
[[ 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0.]]
0.0
for layer_name, blob in net_full_conv.blobs.iteritems():
print layer_name + '\t' + str(blob.data.shape)
data (1, 3, 451, 451)
conv1 (1, 96, 111, 111)
pool1 (1, 96, 55, 55)
norm1 (1, 96, 55, 55)
conv2 (1, 256, 55, 55)
pool2 (1, 256, 27, 27)
norm2 (1, 256, 27, 27)
conv3 (1, 384, 27, 27)
conv4 (1, 384, 27, 27)
conv5 (1, 256, 27, 27)
pool5 (1, 256, 13, 13)
fc6-conv (1, 4096, 8, 8)
fc7-conv (1, 4096, 8, 8)
fc8-conv (1, 1000, 8, 8)
prob (1, 1000, 8, 8)
for layer_name, param in net_full_conv.params.iteritems():
print layer_name + '\t' + str(param[0].data.shape), str(param[1].data.shape)
conv1 (96, 3, 11, 11) (96,)
conv2 (256, 48, 5, 5) (256,)
conv3 (384, 256, 3, 3) (384,)
conv4 (384, 192, 3, 3) (384,)
conv5 (256, 192, 3, 3) (256,)
fc6-conv (4096, 256, 6, 6) (4096,)
fc7-conv (4096, 4096, 1, 1) (4096,)
fc8-conv (1000, 4096, 1, 1) (1000,)
The convolution weights are arranged in output $\times$ input $\times$ height $\times$ width dimensions. To map the inner product weights to convolution filters, we could roll the flat inner product vectors into channel $\times$ height $\times$ width filter matrices, but actually these are identical in memory (as row major arrays) so we can assign them directly.
The biases are identical to those of the inner product.
Let’s transplant!
def print_params():
for pr in params:
print pr, fc_params[pr][0].shape, fc_params[pr][1].shape
for pr in params_full_conv:
print pr, conv_params[pr][0].shape, conv_params[pr][1].shape
pr = 'fc6-conv'
print 'params value for ',pr
print net_full_conv.params[pr][0].data[0,0,:,:]
print net_full_conv.params[pr][1].data[0]
print '*'*50
print '(1) before updated by fc'
print '*'*50
print_params()
#print type(conv_params[pr_conv][0]) # ndarray ndarray.flat
#conv_params[pr_conv][0].flat = fc_params[pr][0].flat
# set w6,w7,w8 of conv from fc w6,w7,w8
for pr, pr_conv in zip(params, params_full_conv):
conv_params[pr_conv][0].flat = fc_params[pr][0].flat # flat unrolls the arrays
conv_params[pr_conv][1][...] = fc_params[pr][1]
print_conv_params = True
print_conv_params = False
if print_conv_params:
pr = 'fc6'
print net.params[pr][0].data[0,:6*6] # no weight_filler,loaded from weights file
print net.params[pr][1].data[0] # no bias_filler,loaded from weights file
print
print 'after init from fc'
pr = 'fc6-conv'
print net_full_conv.params[pr][0].data[0,0,:,:] # no weight_filler,default to 0s, here updated by fc
print net_full_conv.params[pr][1].data[0] # no bias_filler,default to 0s , here updated by fc
print '*'*50
print '(2) after updated by fc'
print '*'*50
print_params()
**************************************************
(1) before updated by fc
**************************************************
fc6 (4096, 9216) (4096,)
fc7 (4096, 4096) (4096,)
fc8 (1000, 4096) (1000,)
fc6-conv (4096, 256, 6, 6) (4096,)
fc7-conv (4096, 4096, 1, 1) (4096,)
fc8-conv (1000, 4096, 1, 1) (1000,)
params value for fc6-conv
[[ 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0.]]
0.0
**************************************************
(2) after updated by fc
**************************************************
fc6 (4096, 9216) (4096,)
fc7 (4096, 4096) (4096,)
fc8 (1000, 4096) (1000,)
fc6-conv (4096, 256, 6, 6) (4096,)
fc7-conv (4096, 4096, 1, 1) (4096,)
fc8-conv (1000, 4096, 1, 1) (1000,)
params value for fc6-conv
[[ 0.00639847 0.00915686 0.00467043 0.00118941 0.00083305 0.00249258]
[ 0.00249609 -0.00354958 -0.00502381 -0.00660044 -0.00810635 -0.00120969]
[-0.00182751 -0.00181385 -0.00327348 -0.00657627 -0.01059825 -0.00223066]
[ 0.00023664 0.00040984 -0.00052619 -0.00124062 -0.00269398 -0.00051081]
[ 0.0014997 0.00123309 -0.00013806 -0.00111619 0.00321043 0.00284487]
[ 0.00051387 -0.00087142 -0.00038937 -0.0008678 0.0049024 0.00155215]]
0.983698
Next, save the new model weights.
net_full_conv.save('net_surgery/bvlc_caffenet_full_conv.caffemodel')
To conclude, let’s make a classification map from the example cat image and visualize the confidence of “tiger cat” as a probability heatmap. This gives an 8-by-8 prediction on overlapping regions of the 451 $\times$ 451 input.
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# load input and configure preprocessing
im = caffe.io.load_image('images/cat.jpg')
transformer = caffe.io.Transformer({'data': net_full_conv.blobs['data'].data.shape}) # (1,3,451,451)
transformer.set_mean('data', np.load('../python/caffe/imagenet/ilsvrc_2012_mean.npy').mean(1).mean(1))
transformer.set_transpose('data', (2,0,1))
transformer.set_channel_swap('data', (2,1,0))
transformer.set_raw_scale('data', 255.0)
transformed_image = transformer.preprocess('data', im)
#print transformed_image.shape #(3, 451, 451)
net_full_conv.blobs['data'].data[...] = transformed_image # (1, 3, 451, 451)
#out = net_full_conv.forward_all(data=np.asarray([transformer.preprocess('data', im)]))
# make classification map by forward and print prediction indices at each location
out = net_full_conv.forward()
prob = out['prob'][0] # (1, 1000, 8, 8)-->(1000, 8, 8)
classification_map = out['prob'][0].argmax(axis=0)
print classification_map # (8,8)
# show net input and confidence map (probability of the top prediction at each location)
plt.subplot(1, 2, 1)
plt.imshow(transformer.deprocess('data', net_full_conv.blobs['data'].data[0]))
plt.subplot(1, 2, 2)
plt.imshow(out['prob'][0,281]) # correct class = 281
plt.colorbar()
plt.tight_layout()
[[282 282 281 281 281 281 277 282]
[281 283 283 281 281 281 281 282]
[283 283 283 283 283 283 287 282]
[283 283 283 281 283 283 283 259]
[283 283 283 283 283 283 283 259]
[283 283 283 283 283 283 259 259]
[283 283 283 283 259 259 259 277]
[335 335 283 259 263 263 263 277]]

The classifications include various cats – 282 = tiger cat, 281 = tabby, 283 = persian – and foxes and other mammals.
In this way the fully connected layers can be extracted as dense features across an image (see net_full_conv.blobs['fc6'].data for instance), which is perhaps more useful than the classification map itself.
Note that this model isn’t totally appropriate for sliding-window detection since it was trained for whole-image classification. Nevertheless it can work just fine. Sliding-window training and finetuning can be done by defining a sliding-window ground truth and loss such that a loss map is made for every location and solving as usual. (This is an exercise for the reader.)
A thank you to Rowland Depp for first suggesting this trick.
net_full_conv.blobs['fc6-conv'].data[0,176,:,:] # (1, 4096, 8, 8)
array([[ 0. , 3.78561878, 4.91759014, 11.89788914,
14.29053116, 16.50216484, 3.7467947 , 0. ],
[ 0. , 17.67206573, 25.0014534 , 39.59349442,
39.08831787, 29.11470604, 9.98679352, 0. ],
[ 1.67216611, 18.15454102, 24.08405876, 39.18917847,
37.54191971, 15.41128445, 0. , 0. ],
[ 0. , 3.00706673, 5.87482309, 15.25675011,
12.55344582, 0. , 0. , 0. ],
[ 0. , 0. , 0. , 0. ,
1. , 0. , 0. , 0. ],
[ 0. , 0. , 0. , 0. ,
1. , 0. , 0. , 0. ],
[ 0. , 0. , 0. , 0. ,
1. , 0. , 0. , 0. ],
[ 0. , 0. , 0. , 0. ,
1. , 0. , 0. , 0. ]], dtype=float32)
Reference
History
- 20180816: created.



