Regex Online Demo
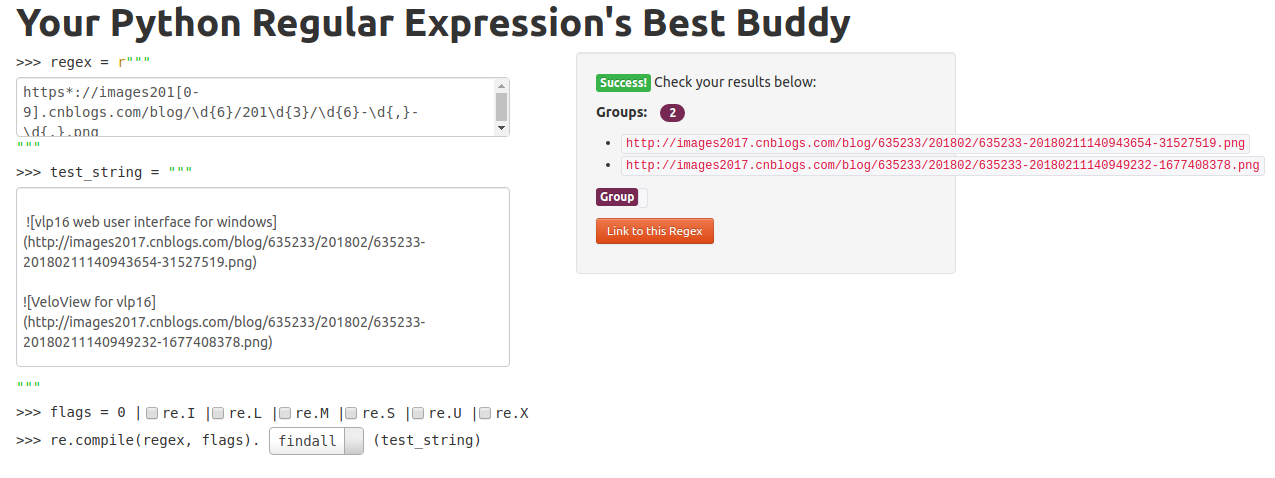
Code Example
import os
import re
import shutil
import requests
def regrex_demo():
pattern = r'https://img201[7-9].cnblogs.com/blog/\d{6}/20\d{4}/\d{6}-\d{,}-\d{,}.png'
string = """
hello world
"""
results = re.findall(pattern,string)
for url in results:
print(url)
def get_filepaths(root_dir):
filepaths = []
for filename in os.listdir(root_dir):
filepath = os.path.sep.join([root_dir, filename])
filepaths.append(filepath)
return filepaths
def makesure_dir(dir):
if not os.path.exists(dir):
os.makedirs(dir)
def find_cnblog_image_urls(filepath):
pattern = r'https*://images201[0-9].cnblogs.com/blog/\d{6,8}/20\d{4}/\d{6,8}-\d{,}-\d{,}.jpg'
urls = []
with open(filepath,"r") as f:
contents = f.read().replace('\n', '')
urls = re.findall(pattern,contents)
return urls
def download_image(url, to_file):
r = requests.get(url, stream=True)
if r.status_code == 200:
with open(to_file, 'wb') as f:
shutil.copyfileobj(r.raw, f)
print("Save to ",to_file)
def download_image_by_chunk(url, to_file):
r = requests.get(url, stream=True)
if r.status_code == 200:
with open(to_file, 'wb') as f:
for chunk in r.iter_content(1024):
f.write(chunk)
print("Save to ",to_file)
def replace_inplace(filepath, old_string, new_string):
f = open(filepath,'r')
filedata = f.read()
f.close()
newdata = filedata.replace(old_string,new_string)
f = open(filepath,'w')
f.write(newdata)
f.close()
def download_image_wrapper(url, to_dir):
"""
donwnload image from url and return new url
"""
filename = url.split("/")[-1]
to_file = os.path.sep.join([to_dir, filename])
download_image(url,to_file)
new_url = "https://kezunlin.me/images/posts/{}".format(filename)
return new_url
def process_all_posts():
to_dir = "images/posts"
makesure_dir(to_dir)
posts_dir = "test_posts"
posts_dir = "_posts"
filepaths = get_filepaths(posts_dir)
for filepath in filepaths:
print("="*20)
print(filepath)
urls = find_cnblog_image_urls(filepath)
for url in urls:
new_url = download_image_wrapper(url,to_dir)
replace_inplace(filepath,url,new_url)
def main():
process_all_posts()
if __name__ =="__main__":
main()
"""
grep -r "cnblogs.com/blog" source/_posts
"""
Reference
History



