Notes
7 knn
- no paramter, with training data as model
- test not fast
no learn anything
8 parameterized learning
- with parameters W,b as model
- test very fast
learn parameters
multi-class svm loss/hinge loss
svm with hinge loss
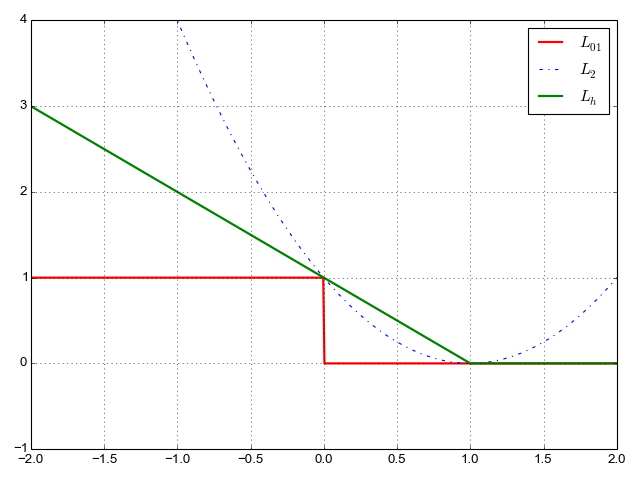
- hinge loss
- squared hinge loss
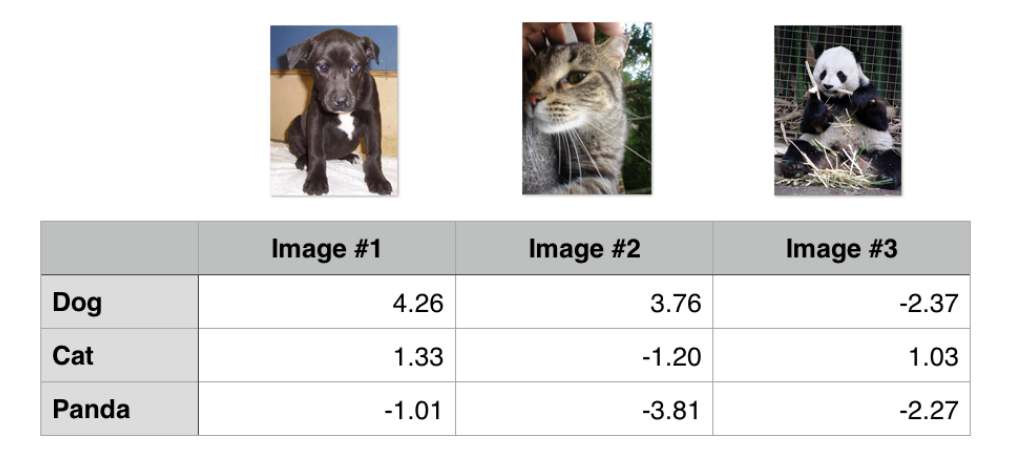
L1 = 0, correct predict
L2 = 5.96, incorrect predict
L3 = 5.20, incorrect predict
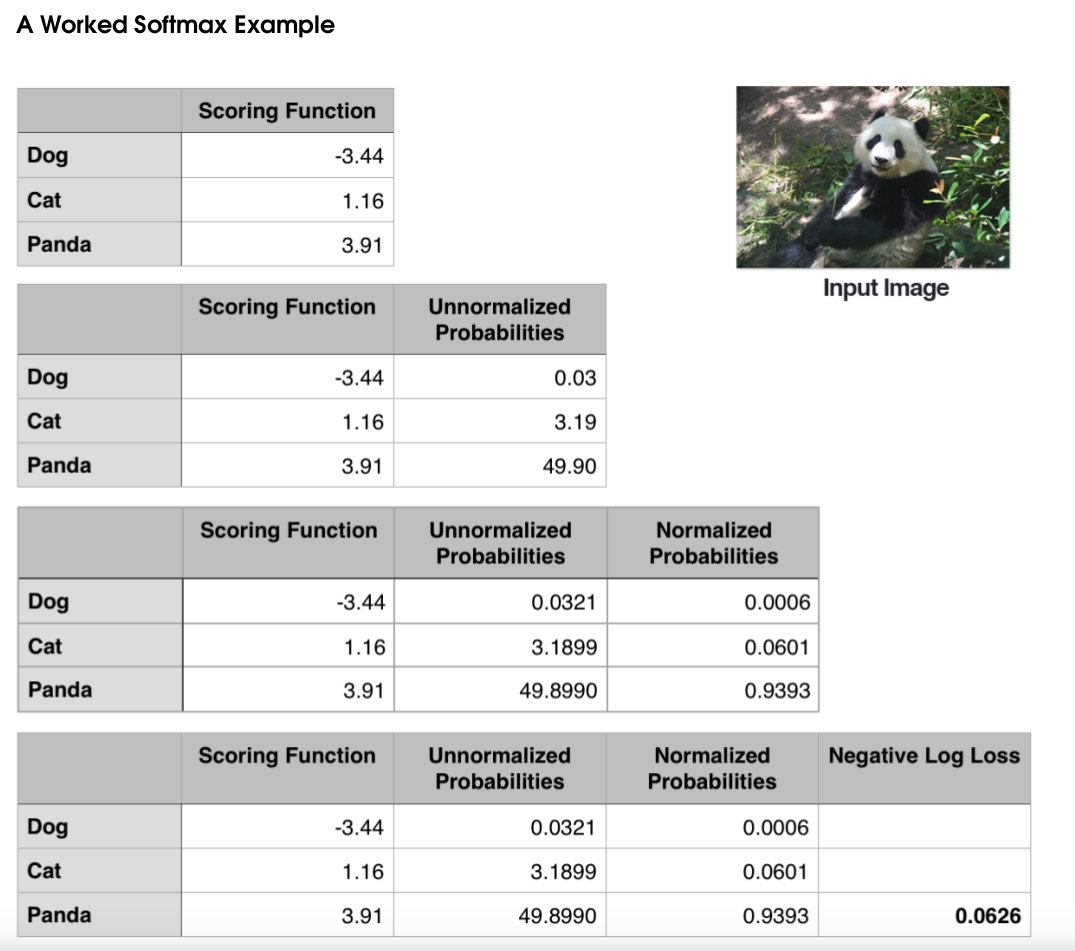
cross-entropy loss and softmax classifiers
Softmax classifiers give you probabilities for each class label while hinge loss gives you the
margin.
9 optimization
GD and SGD
- basic gradient descent(GD): predict all training data and update weights per epoch
- stochastic gradient descent(SGD): predict only batch training data and update weights per batch


Extensions to SGD
- Momentum based SGD
- Nesterov acceration SGD
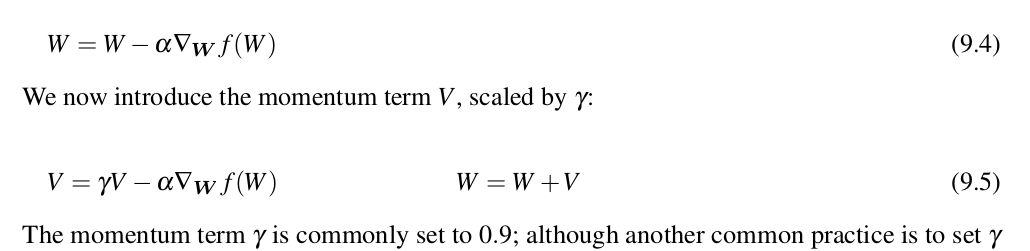
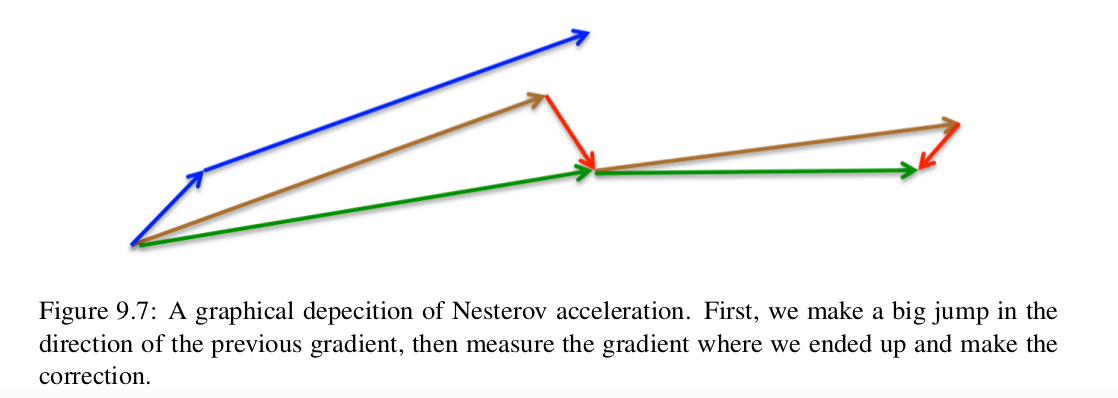
tips: use Momentum based SGD
regularization
add to original cost
- L1 regularization
- L2 regularization(weight decay)
- Elastic Net regularization

during training process
- dropout
- data argumentation
- early stopping(no-imporovements-in-N)
Reference
History
- 20190709: created.



