Series
- Part 1:cpp cuda programming tutorial
- Part 2: cuda activation kernels
- Part 3: cublasSgemm for large matrix multiplication on gpu
Guide
introduction
在异构计算架构中,GPU与CPU通过PCIe总线连接在一起来协同工作,CPU所在位置称为为主机端(host),而GPU所在位置称为设备端(device),如下图所示。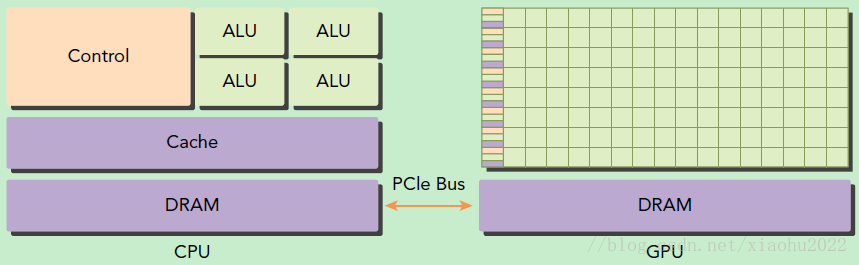
基于CPU+GPU的异构计算平台可以优势互补,CPU负责处理逻辑复杂的串行程序,而GPU重点处理数据密集型的并行计算程序,从而发挥最大功效。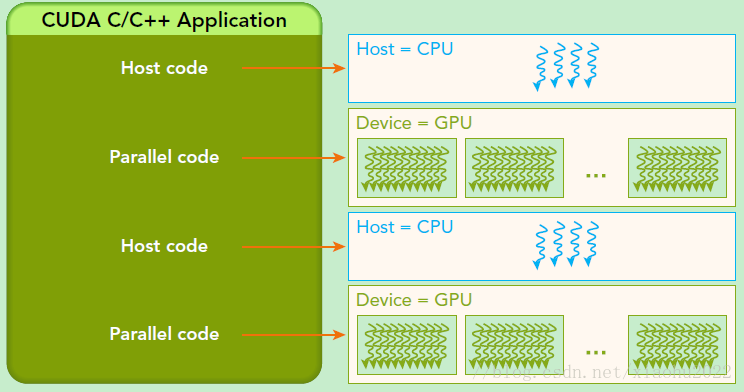
CUDA编程模型基础
- host: CPU,Memory
- device: GPU,Memory
CUDA程序中既包含host程序,又包含device程序,它们分别在CPU和GPU上运行。同时,host与device之间可以进行通信,这样它们之间可以进行数据拷贝。典型的CUDA程序的执行流程如下:
- 分配host内存,并进行数据初始化;
- 分配device内存,并从host将数据拷贝到device上;
- 调用CUDA的核函数(kernel function)在device上完成指定的运算;
- 将device上的运算结果拷贝到host上;
- 释放device和host上分配的内存。
kernel
kernel是CUDA中一个重要的概念,kernel是在device上线程中并行执行的函数,核函数用__global__符号声明,在调用时需要用<<<grid, block>>>来指定kernel要执行的线程数量,在CUDA中,每一个线程都要执行核函数,并且每个线程会分配一个唯一的线程号thread ID,这个ID值可以通过核函数的内置变量threadIdx来获得。
由于GPU实际上是异构模型,所以需要区分host和device上的代码,在CUDA中是通过函数类型限定词开区别host和device上的函数,主要的三个函数类型限定词如下:
__global__:在device上执行,从host中调用(一些特定的GPU也可以从device上调用),返回类型必须是void,不支持可变参数,不能成为类成员函数。注意用__global__定义的kernel是异步的,这意味着host不会等待kernel执行完就执行下一步。__device__:在device上执行,单仅可以从device中调用,不可以和__global__同时用。__host__:在host上执行,仅可以从host上调用,一般省略不写,不可以和__global__同时用,但可和__device__同时用,此时函数会在device和host都编译。
grid/block/thread
1 | dim3 grid(3, 2); |
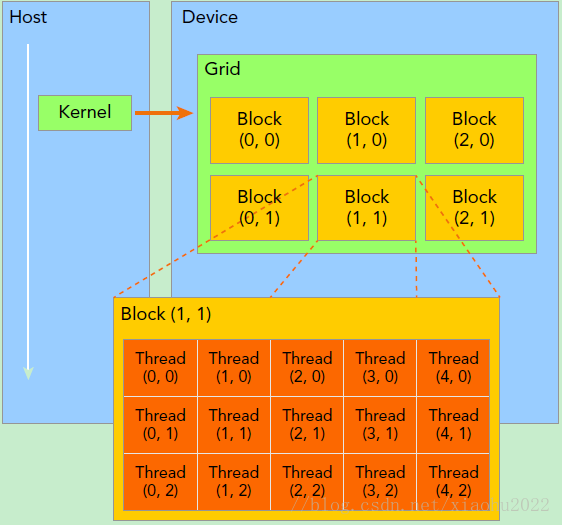
The key is in CUDA’s
<<<1, 1>>>syntax. This is called the execution configuration, and it tells the CUDA runtime how many parallel threads to use for the launch on the GPU.
builtin variables
- threadIdx
- blockIdx
- blockDim
- gridDim
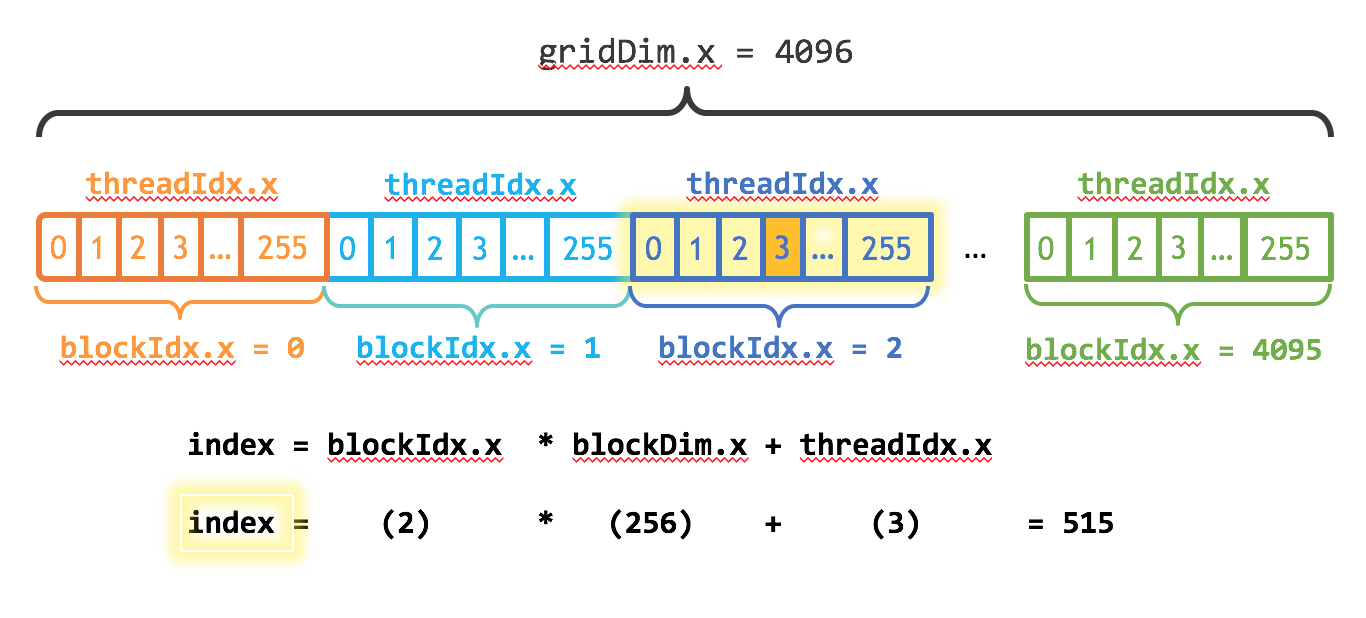
对于一个2-dim的block(Dx,Dy),线程(x,y)的ID值为(x+y∗Dx),
如果是3-dim的block(Dx,Dy,Dz),线程(x,y,z)的ID值为(x+y∗Dx+z∗Dx∗Dy)。
matrix add
1 |
|
CUDA内存模型
gpu memory
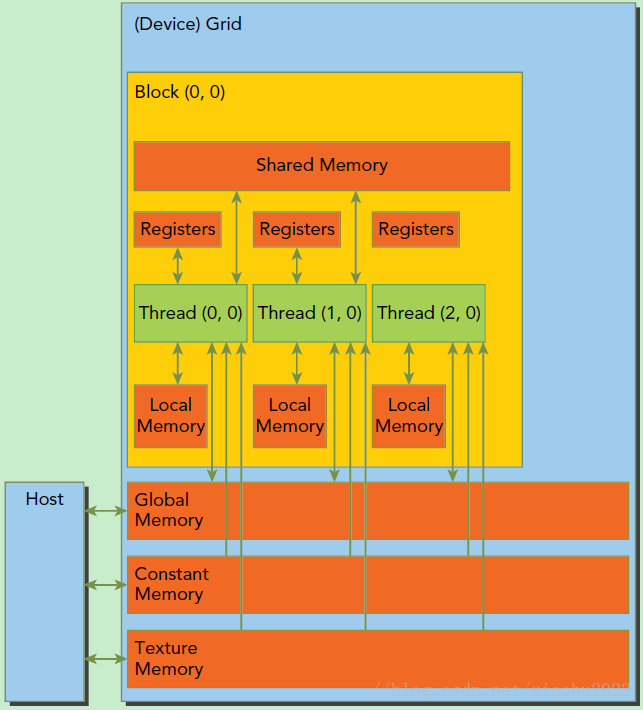
logical/physical layer
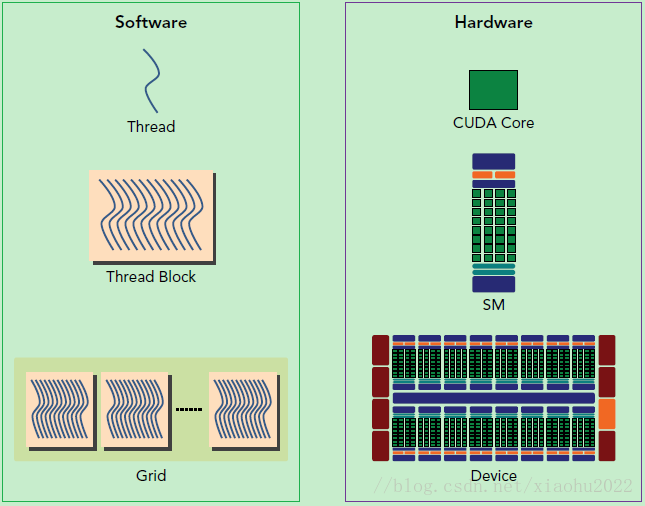
SP最基本的处理单元,Streaming Processor,也称为CUDA core。SM是英文名是Streaming Multiprocessor,翻译过来就是流式多处理器。一个kernel的各个线程块有可能被分配多个
SM,所以grid只是逻辑层,而SM才是执行的物理层。SM采用的是SIMT(Single-Instruction, Multiple-Thread,单指令多线程)架构,基本的执行单元是线程束(wraps),线程束包含32个线程,这些线程同时执行相同的指令,但是每个线程都包含自己的指令地址计数器和寄存器状态,也有自己独立的执行路径。由于
SM的基本执行单元是包含32个线程的线程束,所以block大小一般要设置为32的倍数。每个thread由每个SP执行
每个thread block由SM执行
一个kernel其实由一个grid来执行,一个kernel一次只能在一个GPU上执行
Code
see cuda-demo
CMakeLists.txt
1 | cmake_minimum_required (VERSION 2.8.7) |
vector add
1 |
|
notes for block_size and num_of_blocks
1 | int block_size = 512; |
notes for grid-stride loop
1 | __global__ void kernel_add2(int n, float *a, float *b, float *c) |
nvprof
1 | nvprof.exe demo.exe |
==8748== Profiling application: .\demo.exe
==8748== Profiling result:
Time(%) Time Calls Avg Min Max Name
43.63% 1.6413ms 3 547.10us 517.71us 591.41us [CUDA memcpy HtoD]
30.11% 1.1327ms 1 1.1327ms 1.1327ms 1.1327ms [CUDA memcpy DtoH]
26.26% 987.80us 2 493.90us 243.43us 744.37us kernel_add(int, float*, float*, float*)
at
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\bin\nvprof.exe
matrix multiply
- for 1-dim vector add, we use 1-dim grid and block
- for 2-dim matrix multiply, we use 2-dim grid and block.
1 | // ======================================== |
notes for
1 | dim3 blockSize(32, 32); |
Reference
History
- 20181121: created.