#include<stdio.h> intadd(int x, int y) { return x + y; } int aaa,bbb; // auto zero-intialized(.bss) int ccc000 = 0; // auto zero-initialized(.bss) int ccc111 = 1; // initialized(.data)
int local = 2; // stack int *local_new = newint(5); // heap delete local_new; return0; }
output
g++ hello.cpp
nm a.out
0000000000601078 B aaa
000000000060107c B bbb
000000000060106c B __bss_start
0000000000601080 B ccc000
0000000000601048 D ccc111
0000000000601070 b completed.7594
0000000000601038 D __data_start
0000000000601038 W data_start
00000000004005e0 t deregister_tm_clones
0000000000400660 t __do_global_dtors_aux
0000000000600e08 t __do_global_dtors_aux_fini_array_entry
0000000000601040 D __dso_handle
0000000000600e18 d _DYNAMIC
000000000060106c D _edata
00000000006010a0 B _end
00000000004007a4 T _fini
0000000000400680 t frame_dummy
0000000000600e00 t __frame_dummy_init_array_entry
0000000000400910 r __FRAME_END__
0000000000601000 d _GLOBAL_OFFSET_TABLE_
w __gmon_start__
00000000004007c4 r __GNU_EH_FRAME_HDR
0000000000400530 T _init
0000000000600e08 t __init_array_end
0000000000600e00 t __init_array_start
00000000004007b0 R _IO_stdin_used
w _ITM_deregisterTMCloneTable
w _ITM_registerTMCloneTable
0000000000600e10 d __JCR_END__
0000000000600e10 d __JCR_LIST__
w _Jv_RegisterClasses
00000000004007a0 T __libc_csu_fini
0000000000400730 T __libc_csu_init
U __libc_start_main@@GLIBC_2.2.5
00000000004006ba T main
0000000000400620 t register_tm_clones
U __stack_chk_fail@@GLIBC_2.4
00000000004005b0 T _start
0000000000601050 D str1
0000000000601058 D str2
0000000000601060 D str3
0000000000601088 B str4
0000000000601070 D __TMC_END__
00000000004006a6 T _Z3addii
U _ZdlPv@@GLIBCXX_3.4
0000000000601090 b _ZL3hhh
0000000000601094 b _ZL5iii00
0000000000601064 d _ZL5iii99
00000000004007c0 r _ZL5NUM00
00000000004007bc r _ZL5NUM99
U _Znwm@@GLIBCXX_3.4
0000000000601098 b _ZZ4mainE3jjj
0000000000601068 d _ZZ4mainE3kkk
29 conv 1024 3 x 3 / 1 13 x 13 x1280 -> 13 x 13 x1024 3.987 BF
30 conv 425 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 425 0.147 BF
31 detection
mask_scale: Using default '1.000000'
Total BFLOPS 29.475
Loading weights from ./yolov2.weights...
seen 32
Done!
data/dog.jpg: Predicted in 0.000000 milli-seconds.
dog: 79%
bicycle: 84%
truck: 77%
Not compiled with OpenCV, saving to predictions.png instead
104 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BF
105 conv 255 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 255 0.353 BF
106 yolo
Total BFLOPS 65.864
Loading weights from ./yolov3.weights...
seen 64
Done!
data/dog.jpg: Predicted in 0.000000 milli-seconds.
bicycle: 99%
dog: 100%
truck: 93%
Not compiled with OpenCV, saving to predictions.png instead
view results
1
eog prediction.png
uselib
1
./uselib data/dog.jpg
output
100 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BF
101 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BF
102 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BF
103 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BF
104 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BF
105 conv 255 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 255 0.353 BF
106 yolo
Total BFLOPS 65.864
Loading weights from yolov3.weights...
seen 64
Done!
object names loaded
input image or video filename: dog - obj_id = 16, x = 123, y = 223, w = 196, h = 319, prob = 0.998
truck - obj_id = 7, x = 474, y = 87, w = 216, h = 78, prob = 0.931
bicycle - obj_id = 1, x = 117, y = 124, w = 451, h = 308, prob = 0.99
JetPack 4.1.1 Now supports Host computer running Ubuntu 18.04 or Ubuntu 16.04. JetPack installer can now share host computer’s internet connection to Jetson device via USB Type C cable during install.
可迭代对象(iterable),只定义了__iter__方法; 字符串、列表、元组、字典、文件;可以通过iter(iterable)方法获取iterator对象,也可以通过list(iterable)for xxx in iterable间接调用__iter__方法
迭代器(iterator), Iteration Protocol: 定义了__iter__和__next__两个方法,__iter__返回迭代器本身(用于for loop),__next__方法返回下一个元素,如果没有元素了,抛出StopIteration异常; for python2, use next; for python3, use __next__
iterator = iter(l) #
iterator2 = l.__iter__()
list(l)
for xxx in l:
yrange
例子1:iterable和iterator是同一个对象。
y = iterable()
list(y)
list(y)
for i in y
只有第一次输出所有值;后续输出未空。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classyrange: def__init__(self, n): self.i = 0 self.n = n
def__iter__(self): print("__iter__1") returnself
defnext(self): ifself.i < self.n: i = self.i self.i += 1 return i else: raise StopIteration()
classzrange_iter: def__init__(self, n): self.i = 0 self.n = n
def__iter__(self): print("__iter__2") # Iterators are iterables too. # Adding this functions to make them so. returnself
defnext(self): ifself.i < self.n: i = self.i self.i += 1 return i else: raise StopIteration()
output
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
z = zrange(3) list(z) __iter__1 [0, 1, 2]
list(z) __iter__1 [0, 1, 2]
z = zrange(3) list(z.__iter__()) __iter__1 __iter__2 [0, 1, 2]
list(z.__iter__()) __iter__1 __iter__2 [0, 1, 2]
Generator
Generator functions are ordinary functions defined using yield instead of return. When called, a generator function returns a generator object, which is a kind of iterator - it has a next() method. When you call next(), the next value yielded by the generator function is returned.
use the word “generator” to mean the genearted object and “generator function” to mean the function that generates it.
>>> y = yrange(3) >>> y <generator object yrange at 0x401f30> >>> y.next() 0 >>> y.next() 1 >>> y.next() 2 >>> y.next() Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration
How to work
When a generator function is called, it returns a generator object without even beginning execution of the function. When next method is called for the first time, the function starts executing until it reaches yield statement. The yielded value is returned by the next call.
>>> deffoo(): ... print"begin" ... for i inrange(3): ... print"before yield", i ... yield i ... print"after yield", i ... print"end" ... >>> f = foo() # 不执行任何语句,返回generator object >>> f.next() # 执行语句直到yield,返回结果 begin before yield0 0 >>> f.next() # 从上一次yield语句的下一句开始执行语句直到再次到达yield,返回结果 after yield0 before yield1 1 >>> f.next() # 从上一次yield语句的下一句开始执行语句直到再次到达yield,返回结果 after yield1 before yield2 2 >>> f.next() # 从上一次yield语句的下一句开始执行语句,由于没有再次到达yield所以抛出StopIteration异常 after yield2 end Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration >>>
defintegers(): """Infinite sequence of integers.""" i = 1 whileTrue: yield i i = i + 1
defsquares(): for i in integers(): yield i * i
deftake(n, seq): """Returns first n values from the given sequence.""" seq = iter(seq) result = [] try: for i inrange(n): result.append(seq.next()) except StopIteration: pass return result
print take(5, squares()) # prints [1, 4, 9, 16, 25]
Generator Expressions
Generator Expressions are generator version of list comprehensions. They look like list comprehensions, but returns a generator back instead of a list.
cd cmake && mkdir build && cd build && cmake-gui ..
with options
CMAKE_INSTALL_PREFIX C:/Program Files/protobuf
protobuf_BUILD_SHARED_LIBS ON
Static Linking vs DLL
Static linking is now the default for the Protocol Buffer libraries. Due to issues with Win32’s use of a separate heap for each DLL, as well as binary compatibility issues between different versions of MSVC’s STL library, it is recommended that you use static linkage only. However, it is possible to build libprotobuf and libprotoc as DLLs if you really want. To do this, do the following:
Add an additional flag -Dprotobuf_BUILD_SHARED_LIBS=ON when invoking cmake
Follow the same steps as described in the above section.
When compiling your project, make sure to #define PROTOBUF_USE_DLLS.
compile ALL_BUILD with VS 2015 and install to C:/Program Files/protobuf with dynamic libraries.
Now, in a new terminal, launch TensorBoard with the following shell command:
tensorboard --logdir .
then access http://localhost:6006/#graphs
Session
To evaluate tensors, instantiate a tf.Session object, informally known as a session. A session encapsulates the state of the TensorFlow runtime, and runs TensorFlow operations. If a tf.Graph is like a .py file, a tf.Session is like the python executable.
Reaching the end of the data stream causes Dataset to throw an tf.errors.OutOfRangeError. For example, the following code reads the next_item until there is no more data to read:
Running the inputs tensor will parse the features into a batch of vectors.
Feature columns can have internal state, like layers, so they often need to be initialized. Categorical columns use tf.contrib.lookup internally and these require a separate initialization op, tf.tables_initializer.
# The model hasn't yet been trained, so the four "predicted" values aren't very good. # Here's what we got; your own output will almost certainly differ: print(sess.run(y_pred))
[[0.5062338]
[1.0124676]
[1.5187014]
[2.0249352]]
Loss
To optimize a model, you first need to define the loss. We’ll use the mean square error (MSE), a standard loss for regression problems.
1 2 3
loss = tf.losses.mean_squared_error(labels=y_true, predictions=y_pred)
print(sess.run(loss))
10.484383
Training
TensorFlow provides optimizers implementing standard optimization algorithms. These are implemented as sub-classes of tf.train.Optimizer. They incrementally change each variable in order to minimize the loss. The simplest optimization algorithm is gradient descent, implemented by tf.train.GradientDescentOptimizer.
1 2
optimizer = tf.train.GradientDescentOptimizer(0.01) train = optimizer.minimize(loss) # training operation
1 2 3
for i inrange(100): _, loss_value = sess.run((train, loss)) print(loss_value)
with除了可以进行清理工作之外,真正强大之处是可以处理异常。Sample类的__exit__方法有三个参数:val, type 和 trace。 这些参数在异常处理中相当有用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSample: def__enter__(self): returnself def__exit__(self, type, value, trace): print"type:", type print"value:", value print"trace:", trace defdo_something(self): bar = 1/0 return bar + 10 with Sample() as sample: sample.do_something()
output
type: <type 'exceptions.ZeroDivisionError'>
value: integer division or modulo by zero
trace: <traceback object at 0x0000000004A5AA08>
ZeroDivisionErrorTraceback (most recent call last)
<ipython-input-9-282d3906c5ac> in <module>()
13
14 with Sample() as sample:
---> 15 sample.do_something()
<ipython-input-9-282d3906c5ac> in do_something(self)
9
10 def do_something(self):
---> 11 bar = 1/0
12 return bar + 10
13
ZeroDivisionError: integer division or modulo by zero
set(SUPERDOG_FOUND TRUE) # auto set(SUPERDOG_VERSION 2.3.0) set(SUPERDOG_ROOT_DIR "C:/car_libs/superdog-c-2.3")
find_path(SUPERDOG_INCLUDE_DIR NAMES superdog/dog_api.h PATHS "${SUPERDOG_ROOT_DIR}/include") mark_as_advanced(SUPERDOG_INCLUDE_DIR) # show entry in cmake-gui
find_library(SUPERDOG_LIBRARY NAMES dog_windows_x64_3150436.lib PATHS "${SUPERDOG_ROOT_DIR}/lib") mark_as_advanced(SUPERDOG_LIBRARY) # show entry in cmake-gui
# use xxx_INCLUDE_DIRS and xxx_LIBRARIES in CMakeLists.txt set(SUPERDOG_INCLUDE_DIRS ${SUPERDOG_INCLUDE_DIR} ) set(SUPERDOG_LIBRARIES ${SUPERDOG_LIBRARY} )
inttest_api() { int feature_id = 111; std::string vendor_code = "xxx"; // from `VendorCodes\BYAUY.hvc` MyDogApi dog(feature_id, vendor_code); int status = dog.login(); // 0 OK, other failed (feature id error, vendor_code error, NO SuperDog)
PYBIND11_MODULE(mydog, m) { // optional module docstring m.doc() = "mydog plugin for python ";
// FUNCTIONS // expose add function, and add keyword arguments and default arguments m.def("add", &add, "A function which adds two numbers", py::arg("i") = 1, py::arg("j") = 2);
// DATA // exporting variables m.attr("the_answer") = 42; py::object world = py::cast("World"); m.attr("what") = world;
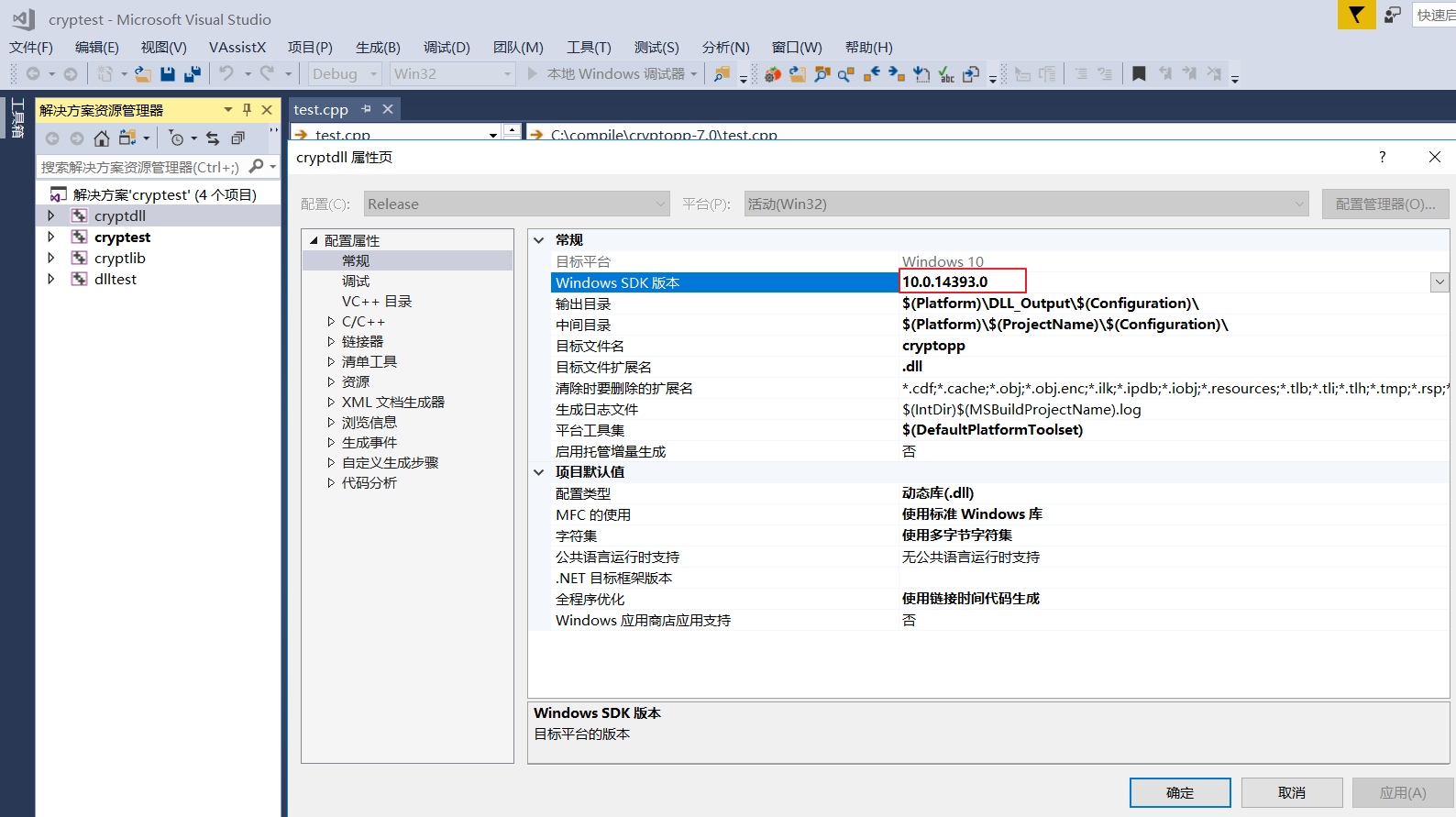
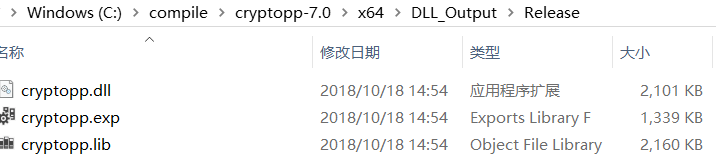
compile cryptodll with Release x64 and we get cryptopp.dll and cryptopp.lib
sdk
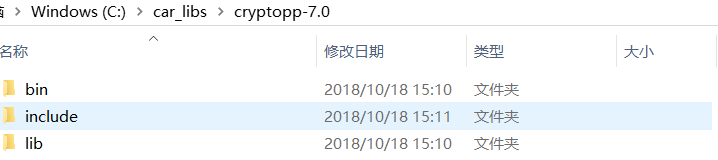
copy headers to include, copy libs to lib and dlls to dll like this:
cryptopp-config.cmake
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
set(CRYPTOPP_FOUND TRUE) # auto set(CRYPTOPP_VERSION 7.0.0) set(CRYPTOPP_ROOT_DIR "C:/car_libs/cryptopp-7.0")
find_path(CRYPTOPP_INCLUDE_DIR NAMES cryptopp/aes.h PATHS "${CRYPTOPP_ROOT_DIR}/include") mark_as_advanced(CRYPTOPP_INCLUDE_DIR) # show entry in cmake-gui
find_library(CRYPTOPP_LIBRARY NAMES cryptopp.lib PATHS "${CRYPTOPP_ROOT_DIR}/lib") mark_as_advanced(CRYPTOPP_LIBRARY) # show entry in cmake-gui
# use xxx_INCLUDE_DIRS and xxx_LIBRARIES in CMakeLists.txt set(CRYPTOPP_INCLUDE_DIRS ${CRYPTOPP_INCLUDE_DIR} ) set(CRYPTOPP_LIBRARIES ${CRYPTOPP_LIBRARY} )
std::string hex_result; for (size_t i = 0; i < str.size(); i++) { std::string c_hex; int uc = (unsignedchar)(str[i]); int a = uc / HEX_BASE; int b = uc % HEX_BASE; c_hex.push_back(HEX[a]); c_hex.push_back(HEX[b]);
$ echo '--help' | xargs cat
Usage: cat [OPTION]... [FILE]...
Concatenate FILE(s) to standard output.
With no FILE, or when FILE is -, read standard input.
-A, --show-all equivalent to -vET
-b, --number-nonblank number nonempty output lines, overrides -n
-e equivalent to -vE
-E, --show-ends display $ at end of each line
-n, --number number all output lines
-s, --squeeze-blank suppress repeated empty output lines
-t equivalent to -vT
-T, --show-tabs display TAB characters as ^I
-u (ignored)
-v, --show-nonprinting use ^ and M- notation, except for LFD and TAB
--help display this help and exit
--version output version information and exit
Examples:
cat f - g Output f's contents, then standard input, then g's contents.
cat Copy standard input to standard output.
GNU coreutils online help: <http://www.gnu.org/software/coreutils/>
Full documentation at: <http://www.gnu.org/software/coreutils/cat>
or available locally via: info '(coreutils) cat invocation'