tesseract --help
Usage:
tesseract --help | --help-extra | --version
tesseract --list-langs
tesseract imagename outputbase [options...] [configfile...]
OCR options:
-l LANG[+LANG] Specify language(s) used for OCR.
NOTE: These options must occur before any configfile.
Single options:
--help Show this help message.
--help-extra Show extra help for advanced users.
--version Show version information.
--list-langs List available languages for tesseract engine.
help-extra
tesseract --help-extra
Usage:
tesseract --help | --help-extra | --help-psm | --help-oem | --version
tesseract --list-langs [--tessdata-dir PATH]
tesseract --print-parameters [options...] [configfile...]
tesseract imagename|imagelist|stdin outputbase|stdout [options...] [configfile...]
OCR options:
--tessdata-dir PATH Specify the location of tessdata path.
--user-words PATH Specify the location of user words file.
--user-patterns PATH Specify the location of user patterns file.
-l LANG[+LANG] Specify language(s) used for OCR.
-c VAR=VALUE Set value for config variables.
Multiple -c arguments are allowed.
--psm NUM Specify page segmentation mode.
--oem NUM Specify OCR Engine mode.
NOTE: These options must occur before any configfile.
Page segmentation modes:
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
OCR Engine modes: (see https://github.com/tesseract-ocr/tesseract/wiki#linux)
0 Legacy engine only.
1 Neural nets LSTM engine only.
2 Legacy + LSTM engines.
3 Default, based on what is available.
Single options:
-h, --help Show minimal help message.
--help-extra Show extra help for advanced users.
--help-psm Show page segmentation modes.
--help-oem Show OCR Engine modes.
-v, --version Show version information.
--list-langs List available languages for tesseract engine.
--print-parameters Print tesseract parameters.
run script
1 2 3 4 5 6
python text_recognition.py --east frozen_east_text_detection.pb \ --image images/example_01.jpg [INFO] loading EAST text detector... OCR TEXT ======== OH OK
However, our py2 virtual environment is located in our home directory — thus to use OpenCV within our py2 environment, we first need to sym-link OpenCV into the site-packages directory of the py2 virtual environment:
> 1. DO NOT install nvidia driver, install cuda toolkit + samples. > > 2. use default install path `/usr/local/cuda-9.2` > > 3. use `/usr/local/cuda-9.2/bin/uninstall_cuda_9.2.pl` to uninstall
```bash chmod +x ./cuda_9.2.148_396.37_linux.run
# Using unspported compiler---> override ./cuda_9.2.148_396.37_linux.run --override
output
---------------------------------------
Do you accept the previously read EULA?
(accept/decline/quit): accept
Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 396.37? (y)es/(n)o/(q)uit: no
Install the CUDA 9.2 Toolkit?
(y)es/(n)o/(q)uit: yes
Enter Toolkit Location
[ default is /usr/local/cuda-9.2 ]:
Do you want to install a symbolic link at /usr/local/cuda? (y)es/(n)o/(q)uit: yes
Install the CUDA 9.2 Samples?
(y)es/(n)o/(q)uit: yes
Enter CUDA Samples Location
[ default is /home/kezunlin ]:
Installing the CUDA Toolkit in /usr/local/cuda-9.2 ...
Installing the CUDA Samples in /home/kezunlin ...
===========
= Summary =
===========
Driver: Not Selected
Toolkit: Installed in /usr/local/cuda-9.2
Samples: Installed in /home/kezunlin
Please make sure that
- PATH includes /usr/local/cuda-9.2/bin
- LD_LIBRARY_PATH includes /usr/local/cuda-9.2/lib64, or, add /usr/local/cuda-9.2/lib64 to /etc/ld.so.conf and run ldconfig as root
To uninstall the CUDA Toolkit, run the uninstall script in /usr/local/cuda-9.2/bin
Please see CUDA_Installation_Guide_Linux.pdf in /usr/local/cuda-9.2/doc/pdf for detailed information on setting up CUDA.
***WARNING: Incomplete installation! This installation did not install the CUDA Driver. A driver of version at least 384.00 is required for CUDA 9.2 functionality to work.
To install the driver using this installer, run the following command, replacing <CudaInstaller> with the name of this run file:
sudo <CudaInstaller>.run -silent -driver
Logfile is /tmp/cuda_install_6659.log
reboot to enter GUI
1
sudo reboot
OK. we no longer have Loop Login Problem.
add library path
system env
1 2 3 4 5 6 7
vim .bashrc
# for cuda and cudnn export PATH=/usr/local/cuda/bin:$PATH export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
source .bashrc
or by conf file
1 2 3 4
sudo vim /etc/ld.so.conf.d/cuda.conf /usr/local/cuda/lib64
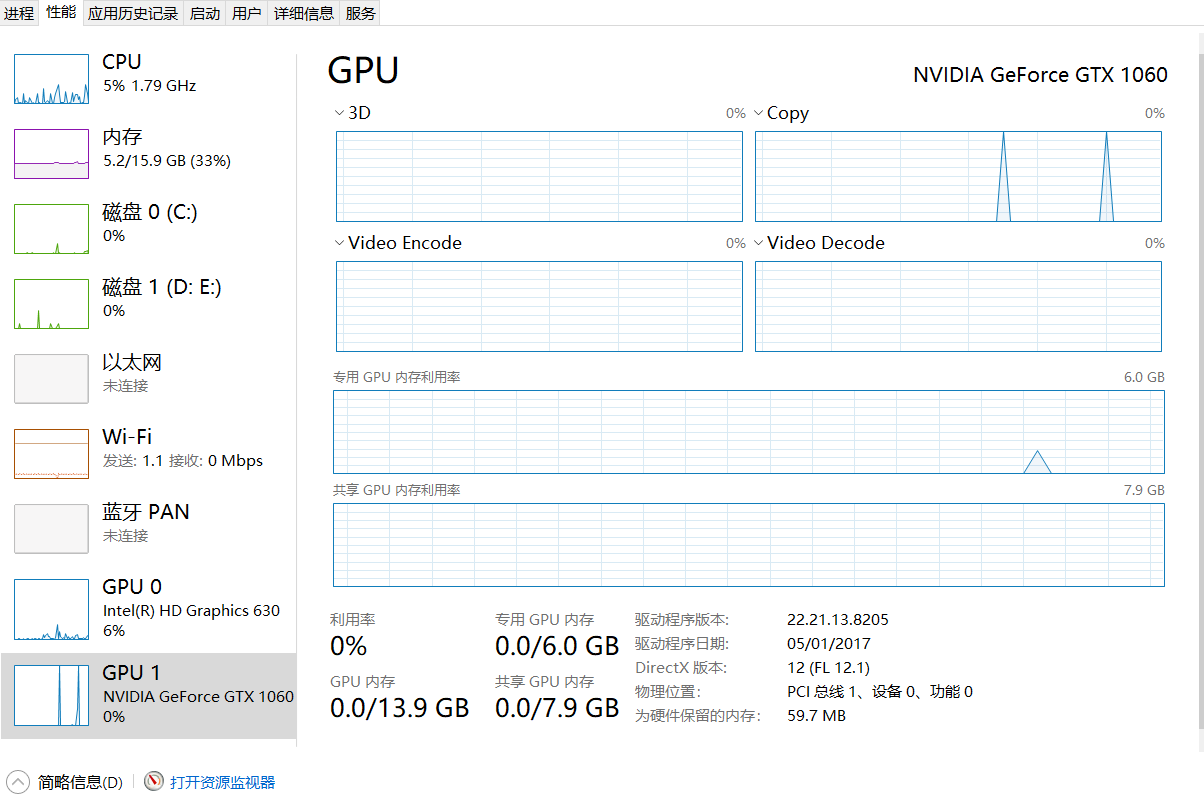
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce GTX 1060" CUDA Driver Version / Runtime Version 9.2 / 9.2 CUDA Capability Major/Minor version number: 6.1 Total amount of global memory: 6078 MBytes (6373572608 bytes) (10) Multiprocessors, (128) CUDA Cores/MP: 1280 CUDA Cores GPU Max Clock rate: 1733 MHz (1.73 GHz) Memory Clock rate: 4004 Mhz Memory Bus Width: 192-bit L2 Cache Size: 1572864 bytes Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384) Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers Total amount of constant memory: 65536 bytes Total amount of shared memory per block: 49152 bytes Total number of registers available per block: 65536 Warp size: 32 Maximum number of threads per multiprocessor: 2048 Maximum number of threads per block: 1024 Max dimension size of a thread block (x,y,z): (1024, 1024, 64) Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535) Maximum memory pitch: 2147483647 bytes Texture alignment: 512 bytes Concurrent copy and kernel execution: Yes with 2 copy engine(s) Run time limit on kernels: Yes Integrated GPU sharing Host Memory: No Support host page-locked memory mapping: Yes Alignment requirement for Surfaces: Yes Device has ECC support: Disabled Device supports Unified Addressing (UVA): Yes Device supports Compute Preemption: Yes Supports Cooperative Kernel Launch: Yes Supports MultiDevice Co-op Kernel Launch: Yes Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0 Compute Mode: < Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 9.2, CUDA Runtime Version = 9.2, NumDevs = 1 Result = PASS
we get Result = PASS.
install cudnn
download cudnn-9.2-linux-x64-v7.1.tgz for ubuntu 16.04
copy include to /usr/local/cuda-9.2/include
copy lib64 to /usr/local/cuda-9.2/lib64
commands
1 2 3
tar -xzvf cudnn-9.2-linux-x64-v7.1.tgz sudocp cuda/include/cudnn.h /usr/local/cuda/include/ sudocp cuda/lib64/* /usr/local/cuda/lib64/
tree bin bin ├── download-digits-model.py ├── giexec └── trtexec
sample
add envs
1 2 3 4 5
vim ~/.bashrc
# tensorrt cuda and cudnn export CUDA_INSTALL_DIR=/usr/local/cuda export CUDNN_INSTALL_DIR=/usr/local/cuda
compile all
1 2
cd samples/ make -j8
generate all sample_xxx to bin/ folder.
compile sampleMNIST
1 2 3 4
cd samples/sampleMNIST ls Makefile sampleMNIST.cpp make -j8
error occurs
dpkg-query: no packages found matching cuda-cudart-[0-9]*
../Makefile.config:6: CUDA_INSTALL_DIR variable is not specified, using /usr/local/cuda- by default, use CUDA_INSTALL_DIR=<cuda_directory> to change.
../Makefile.config:9: CUDNN_INSTALL_DIR variable is not specified, using by default, use CUDNN_INSTALL_DIR=<cudnn_directory> to change.
fix solutions:
1 2 3 4 5
vim ~/.bashrc
# tensorrt cuda and cudnn export CUDA_INSTALL_DIR=/opt/cuda export CUDNN_INSTALL_DIR=/opt/cuda
make again
:
:
Compiling: sampleMNIST.cpp
Compiling: sampleMNIST.cpp
Linking: ../../bin/sample_mnist
Linking: ../../bin/sample_mnist_debug
# Copy every EXTRA_FILE of this sample to bin dir
./sample_int8 mnist
FP32 run:400 batches of size 100 starting at 100
........................................
Top1: 0.9904, Top5: 1
Processing 40000 images averaged 0.00332707 ms/image and 0.332707 ms/batch.
FP16 run:400 batches of size 100 starting at 100
Engine could not be created at this precision
INT8 run:400 batches of size 100 starting at 100
........................................
Top1: 0.9909, Top5: 1
Processing 40000 images averaged 0.00215323 ms/image and 0.215323 ms/batch.
template<typename TargetType, DataType Dtype, Precision Ptype>
class Graph ... /* inherit other class*/{
//some implements
...
};
load
//some declarations
...
auto graph = new Graph<NV, AK_FLOAT, Precision::FP32>();
std::string model_path = "the/path/to/where/your/models/are";
const char *model_path1 = "the/path/to/where/your/models/are";
//Loading Anakin model to generate a compute graph.
auto status = graph->load(model_path);
//Or this way.
auto status = graph->load(model_path1);
//Check whether load operation success.
if(!status){
std::cout << "error" << endl;
//do something...
}
optimize
//some declarations
...
//Load graph.
...
//According to the ops of loaded graph, optimize compute graph.
graph->Optimize();
save
//some declarations
...
//Load graph.
...
// save a model
//save_model_path: the path to where your model is.
auto status = graph->save(save_model_path);
//Checking
if(!status){
cout << "error" << endl;
//do somethin...
}
//some declarations
...
//Create a pointer to a graph.
auto graph = new Graph<NV, AK_FLOAT, Precision::FP32>();
//do something...
...
//create a executor
Net<NV, AK_FLOAT, Precision::FP32> executor(*graph);
get input tensor
//some declaratinos
...
//create a executor
//TargetType is NV [NVIDIA GPU]
Net<NV, AK_FLOAT, Precision::FP32> executor(*graph);
//Get the first input tensor.
//The following tensors(tensor_in0, tensor_in2 ...) are resident at GPU.
//Note: Member function get_in returns an pointer to tensor.
Tensor<NV, AK_FLOAT>* tensor_in0 = executor.get_in("input_0");
//If you have multiple input tensors
//You just type this code below.
Tensor<NV, AK_FLOAT>* tensor_in1 = executor.get_in("input_1");
...
auto tensor_inn = executor.get_in("input_n");
fill input tensor
//This tensor is resident at GPU.
auto tensor_d_in = executor.get_in("input_0");
//If we want to feed above tensor, we must feed the tensor which is resident at host. And then copy the host tensor to the device's one.
//using Tensor4d = Tensor<Ttype, Dtype>;
Tensor4d<X86, AK_FLOAT> tensor_h_in; //host tensor;
//Tensor<X86, AK_FLOAT> tensor_h_in;
//Allocate memory for host tensor.
tensor_h_in.re_alloc(tensor_d_in->valid_shape());
//Get a writable pointer to tensor.
float *h_data = tensor_h_in.mutable_data();
//Feed your tensor.
/** example
for(int i = 0; i < tensor_h_in.size(); i++){
h_data[i] = 1.0f;
}
*/
//Copy host tensor's data to device tensor.
tensor_d_in->copy_from(tensor_h_in);
// And then
get output tensor
//Note: this tensor are resident at GPU.
Tensor<NV, AK_FLOAT>* tensor_out_d = executor.get_out("pred_out");
std::string model_path = "your_Anakin_models/xxxxx.anakin.bin"; // Create an empty graph object. auto graph = newGraph<NV, AK_FLOAT, Precision::FP32>(); // Load Anakin model. auto status = graph->load(model_path); if(!status ) { LOG(FATAL) << " [ERROR] " << status.info(); } // Reshape graph->Reshape("input_0", {10, 384, 960, 10}); // You must optimize graph for the first time. graph->Optimize(); // Create a executer. Net<NV, AK_FLOAT, Precision::FP32> net_executer(*graph);
//Get your input tensors through some specific string such as "input_0", "input_1", and //so on. //And then, feed the input tensor. //If you don't know Which input do these specific string ("input_0", "input_1") correspond with, you can launch dash board to find out. auto d_tensor_in_p = net_executer.get_in("input_0"); Tensor4d<X86, AK_FLOAT> h_tensor_in; auto valid_shape_in = d_tensor_in_p->valid_shape(); for (int i=0; i<valid_shape_in.size(); i++) { LOG(INFO) << "detect input dims[" << i << "]" << valid_shape_in[i]; //see tensor's dimentions } h_tensor_in.re_alloc(valid_shape_in); float* h_data = h_tensor_in.mutable_data(); for (int i=0; i<h_tensor_in.size(); i++) { h_data[i] = 1.0f; } d_tensor_in_p->copy_from(h_tensor_in);
//Do inference. net_executer.prediction();
//Get result tensor through the name of output node. //And also, you need to see the dash board again to find out how many output nodes are and remember their name.
//For example, you've got a output node named obj_pre_out //Then, you can get an output tensor. auto d_tensor_out_0_p = net_executer.get_out("obj_pred_out"); //get_out returns a pointer to output tensor. auto d_tensor_out_1_p = net_executer.get_out("lc_pred_out"); //get_out returns a pointer to output tensor. //...... // do something else ... //... //save model. //You might not optimize the graph when you load the saved model again. std::string save_model_path = model_path + std::string(".saved"); auto status = graph->save(save_model_path); if (!status ) { LOG(FATAL) << " [ERROR] " << status.info(); }
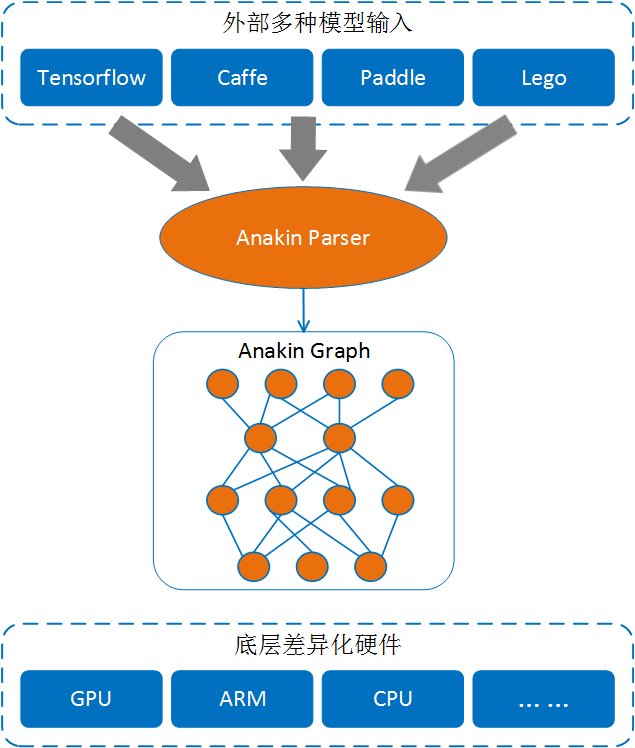
anakin converter
1 2 3 4 5 6
cd anakin/tools/external_converter_v2 sudo pip install flask prettytable
TARGET: CAFFE: # path to proto files ProtoPaths: -/home/kezunlin/program/caffe/src/caffe/proto/caffe.proto PrototxtPath:/home/kezunlin/program/caffe/examples/mnist/lenet.prototxt ModelPath:/home/kezunlin/program/caffe/examples/mnist/lenet_iter_10000.caffemodel
FLUID: # path of fluid inference model Debug:NULL# Generally no need to modify. ModelPath:/path/to/your/model/# The upper path of a fluid inference model. NetType:# Generally no need to modify. LEGO: # path to proto files ProtoPath: PrototxtPath: ModelPath: TENSORFLOW: ProtoPaths:/ PrototxtPath:/ ModelPath:/ OutPuts: ONNX: ProtoPath: PrototxtPath: ModelPath:
Mat image = imread("../image/cat.jpg",0); cv::resize(image,image,Size(28,28)); //imshow("image",image); //waitKey(0);
/*init graph object, graph is the skeleton of model*/ Graph<NV, AK_FLOAT, Precision::FP32> graph;
/*load model from file to init the graph*/ auto status = graph.load(model_path); if (!status) { LOG(FATAL) << " [ERROR] " << status.info(); }
/*set net input shape and use this shape to optimize the graph(fusion and init operator),shape is n,c,h,w*/ graph.Reshape("input_0", {1, 1, 28, 28}); graph.Optimize();
/*net_executer is the executor object of model. use graph to init Net*/ Net<NV, AK_FLOAT, Precision::FP32> net_executer(graph, true);
/*use input string to get the input tensor of net. for we use NV as target, the tensor of net_executer is on GPU memory*/ auto d_tensor_in_p = net_executer.get_in("input_0"); auto valid_shape_in = d_tensor_in_p->valid_shape();
/*create tensor located in host*/ Tensor4d<X86, AK_FLOAT> h_tensor_in;
/*alloc for host tensor*/ h_tensor_in.re_alloc(valid_shape_in);
/*init host tensor by random*/ //fill_tensor_host_rand(h_tensor_in, -1.0f, 1.0f);
/*use host tensor to int device tensor which is net input*/ d_tensor_in_p->copy_from(h_tensor_in);
/*run infer*/ net_executer.prediction();
LOG(INFO)<<"infer finish";
/*get the out put of net, which is a device tensor*/ auto d_out=net_executer.get_out("prob_out");
/*create another host tensor, and copy the content of device tensor to host*/ Tensor4d<X86, AK_FLOAT> h_tensor_out; h_tensor_out.re_alloc(d_out->valid_shape()); h_tensor_out.copy_from(*d_out);
#git clone https://github.com/PaddlePaddle/Anakin.git anakin git clone https://github.com/kezunlin/Anakin.git anakin cd anakin mkdir build && cd build && cmake-gui ..
with options
CUDNN_ROOT "C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v8.0/"
PROTOBUF_ROOT "C:/Program Files/protobuf"
BUILD_SHARED ON
USE_GPU_PLACE ON
USE_OPENMP OFF
USE_OPENCV ON
generate Anakin.sln and compile with VS 2015 with x64 Release mode.
The machine running the CUDA container only requires the NVIDIA driver, the CUDA toolkit doesn’t have to be installed. Host系统只需要安装NVIDIA driver即可运行CUDA container。
install
remove nvidia-docker 1.0
1 2 3
# If you have nvidia-docker 1.0 installed: we need to remove it and all existing GPU containers docker volume ls -q -f driver=nvidia-docker | xargs -r -I{} -n1 docker ps -q -a -f volume={} | xargs -r docker rm -f sudo apt-get purge -y nvidia-docker
The default runtime used by the Docker® Engine is runc, our runtime can become the default one by configuring the docker daemon with --default-runtime=nvidia. Doing so will remove the need to add the --runtime=nvidia argument to docker run. It is also the only way to have GPU access during docker build.
Environment variables
The behavior of the runtime can be modified through environment variables (such as NVIDIA_VISIBLE_DEVICES). Those environment variables are consumed by nvidia-container-runtime and are documented here. Our official CUDA images use default values for these variables.
docker command
1 2 3 4 5 6 7 8
sudo docker image list REPOSITORY TAG IMAGE ID CREATED SIZE nvidia/cuda latest 04a9ce0dec6d 3 weeks ago 1.96GB
python3 Python 3.5.3 (v3.5.3:1880cb95a742, Jan 16 2017, 16:02:32) [MSC v.1900 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license"for more information. >>> ^Z
pip3
1 2
pip3 -V pip 9.0.1 from c:\users\zunli\appdata\local\programs\python\python35\lib\site-packages (python 3.5)
b = tf.test.is_gpu_available( cuda_only=False, min_cuda_compute_capability=None ) # 判断GPU是否可以用
print(a) print(b)
test gpu
1 2 3 4 5 6 7 8 9 10 11 12 13 14
import tensorflow as tf
with tf.device('/cpu:0'): a = tf.constant([1.0, 2.0, 3.0], shape=[3], name='a') b = tf.constant([1.0, 2.0, 3.0], shape=[3], name='b') with tf.device('/gpu:0'): c = a + b
We can capture external variables from enclosing scope by three ways :
Capture by reference
Capture by value (making a copy)
Capture by both (mixed capture)
Syntax used for capturing variables :
[]: capture nothing
[&] : capture all external variable by reference
[=] : capture all external variable by value (making a copy)
[a, &b] : capture a by value and b by reference
[this] : Capture the this pointer of the enclosing class
// capture nothing std::sort(v.begin(), v.end(), [](constint& a, constint& b) -> bool { return a > b; }); printVector(v);
int ans = accumulate(v.begin(),v.end(),0, [](int i,int j) { return i+j; } ); cout << "SUM = " << ans << endl; }
voidtest_lambda_2() { vector<int> v1 = {3, 1, 7, 9}; vector<int> v2 = {10, 2, 7, 16, 9}; // access v1 and v2 by reference auto pushinto = [&] (int m) { v1.push_back(m); v2.push_back(m); }; // it pushes 20 in both v1 and v2 pushinto(20);
// access v1 by value (copy) auto printv = [v1]() { for (auto p = v1.begin(); p != v1.end(); p++) { cout << *p << " "; } cout << endl; }; printv();
int N = 5; // below snippet find first number greater than N // [N] denotes, can access only N by value vector<int>:: iterator p = find_if(v1.begin(), v1.end(), [N](int i) { return i > N; }); cout << "First number greater than 5 is : " << *p << endl; }
classFoo { public: Foo () : _x( 3 ) {} voidfunc() { // a very silly, but illustrative way of printing out the value of _x [this] () { cout << this->_x; } (); }
voidget_color_table() { // cache color value in table[256] int divideWith = 10; uchar table[256]; for (int i = 0; i < 256; ++i) table[i] = divideWith* (i / divideWith); }
// C ptr []: faster but not safe Mat& ScanImageAndReduce_Cptr(Mat& I, const uchar* const table) { // accept only char type matrices CV_Assert(I.depth() != sizeof(uchar)); int channels = I.channels(); int nRows = I.rows; int nCols = I.cols* channels; if (I.isContinuous()) { nCols *= nRows; nRows = 1; } int i, j; uchar* p; for (i = 0; i < nRows; ++i) { p = I.ptr<uchar>(i); for (j = 0; j < nCols; ++j) { p[j] = table[p[j]]; } } return I; }
// MatIterator_<uchar>: safe but slow Mat& ScanImageAndReduce_Iterator(Mat& I, const uchar* const table) { // accept only char type matrices CV_Assert(I.depth() != sizeof(uchar)); constint channels = I.channels(); switch (channels) { case1: { MatIterator_<uchar> it, end; for (it = I.begin<uchar>(), end = I.end<uchar>(); it != end; ++it) *it = table[*it]; break; } case3: { MatIterator_<Vec3b> it, end; for (it = I.begin<Vec3b>(), end = I.end<Vec3b>(); it != end; ++it) { (*it)[0] = table[(*it)[0]]; (*it)[1] = table[(*it)[1]]; (*it)[2] = table[(*it)[2]]; } } } return I; }
opencv LUT
1 2 3 4 5 6 7 8 9 10 11
// LUT Mat& ScanImageAndReduce_LUT(Mat& I, const uchar* const table) { Mat lookUpTable(1, 256, CV_8U); uchar* p = lookUpTable.data; for (int i = 0; i < 256; ++i) p[i] = table[i];
cv::LUT(I, lookUpTable, I); return I; }
forEach
forEach method of the Mat class that utilizes all the cores on your machine to apply any function at every pixel.
// Parallel execution with function object. structForEachOperator { uchar m_table[256]; ForEachOperator(const uchar* const table) { for (size_t i = 0; i < 256; i++) { m_table[i] = table[i]; } }
voidoperator()(uchar& p, constint * position)const { // Perform a simple operation p = m_table[p]; } };
// forEach use multiple processors, very fast Mat& ScanImageAndReduce_forEach(Mat& I, const uchar* const table) { I.forEach<uchar>(ForEachOperator(table)); return I; }
forEach with lambda
1 2 3 4 5 6 7 8 9 10 11 12
// forEach lambda use multiple processors, very fast (lambda slower than ForEachOperator) Mat& ScanImageAndReduce_forEach_with_lambda(Mat& I, const uchar* const table) { I.forEach<uchar> ( [=](uchar &p, constint * position) -> void { p = table[p]; } ); return I; }
time cost
no foreach
[1 Cptr ] times=5000, total_cost=988 ms, avg_cost=0.1976 ms
[1 Cptr2 ] times=5000, total_cost=1704 ms, avg_cost=0.3408 ms
[2 atRandom] times=5000, total_cost=9611 ms, avg_cost=1.9222 ms
[3 Iterator] times=5000, total_cost=20195 ms, avg_cost=4.039 ms
[4 LUT ] times=5000, total_cost=899 ms, avg_cost=0.1798 ms
[1 Cptr ] times=10000, total_cost=2425 ms, avg_cost=0.2425 ms
[1 Cptr2 ] times=10000, total_cost=3391 ms, avg_cost=0.3391 ms
[2 atRandom] times=10000, total_cost=20024 ms, avg_cost=2.0024 ms
[3 Iterator] times=10000, total_cost=39980 ms, avg_cost=3.998 ms
[4 LUT ] times=10000, total_cost=103 ms, avg_cost=0.0103 ms
foreach
[5 forEach ] times=200000, total_cost=199 ms, avg_cost=0.000995 ms
[5 forEach lambda] times=200000, total_cost=521 ms, avg_cost=0.002605 ms
[5 forEach ] times=20000, total_cost=17 ms, avg_cost=0.00085 ms
[5 forEach lambda] times=20000, total_cost=23 ms, avg_cost=0.00115 ms
# import the necessary packages import matplotlib.pyplot as plt import cv2 print(cv2.__version__)
%matplotlib inline
3.4.2
1 2 3 4 5 6
# load the original image, convert it to grayscale, and display # it inline image = cv2.imread("cat.jpg") image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) print(image.shape) #plt.imshow(image, cmap="gray")
(360, 480)
1
%load_ext cython
The cython extension is already loaded. To reload it, use:
%reload_ext cython
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
%%cython -a def threshold_python(T, image): # grab the image dimensions h = image.shape[0] w = image.shape[1] # loop over the image, pixel by pixel for y in range(0, h): for x in range(0, w): # threshold the pixel image[y, x] = 255 if image[y, x] >= T else 0 # return the thresholded image return image
1
%timeit threshold_python(5, image)
263 ms ± 20.2 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%%cython -a import cython @cython.boundscheck(False) cpdef unsigned char[:, :] threshold_cython(int T, unsigned char [:, :] image): # set the variable extension types cdef int x, y, w, h # grab the image dimensions h = image.shape[0] w = image.shape[1] # loop over the image for y in range(0, h): for x in range(0, w): # threshold the pixel image[y, x] = 255 if image[y, x] >= T else 0 # return the thresholded image return image
numba
1
%timeit threshold_cython(5, image)
150 µs ± 7.14 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
from numba import njit
@njit defthreshold_njit(T, image): # grab the image dimensions h = image.shape[0] w = image.shape[1] # loop over the image, pixel by pixel for y inrange(0, h): for x inrange(0, w): # threshold the pixel image[y, x] = 255if image[y, x] >= T else0 # return the thresholded image return image
1
%timeit threshold_njit(5, image)
43.5 µs ± 142 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)