Series
- Part 1: install and configure tensorrt 4 on ubuntu 16.04
- Part 2: tensorrt fp32 fp16 tutorial
- Part 3: tensorrt int8 tutorial
Guide
FP32/FP16/INT8 range
INT8 has significantly lower precision and dynamic range compared to FP32.

High-throughput INT8 math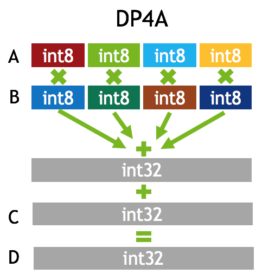
DP4A: int8 dot product Requires
sm_61+(Pascal TitanX, GTX 1080, Tesla P4, P40 and others).
Calibration Dataset
When preparing the calibration dataset, you should capture the expected distribution of data in typical inference scenarios. You want to make sure that the calibration dataset covers all the expected scenarios; for example, clear weather, rainy day, night scenes, etc. If you are creating your own dataset, we recommend creating a separate calibration dataset. The calibration dataset shouldn’t overlap with the training, validation or test datasets, in order to avoid a situation where the calibrated model only works well on the these datasets.
具有代表性,最好是val set的子集。
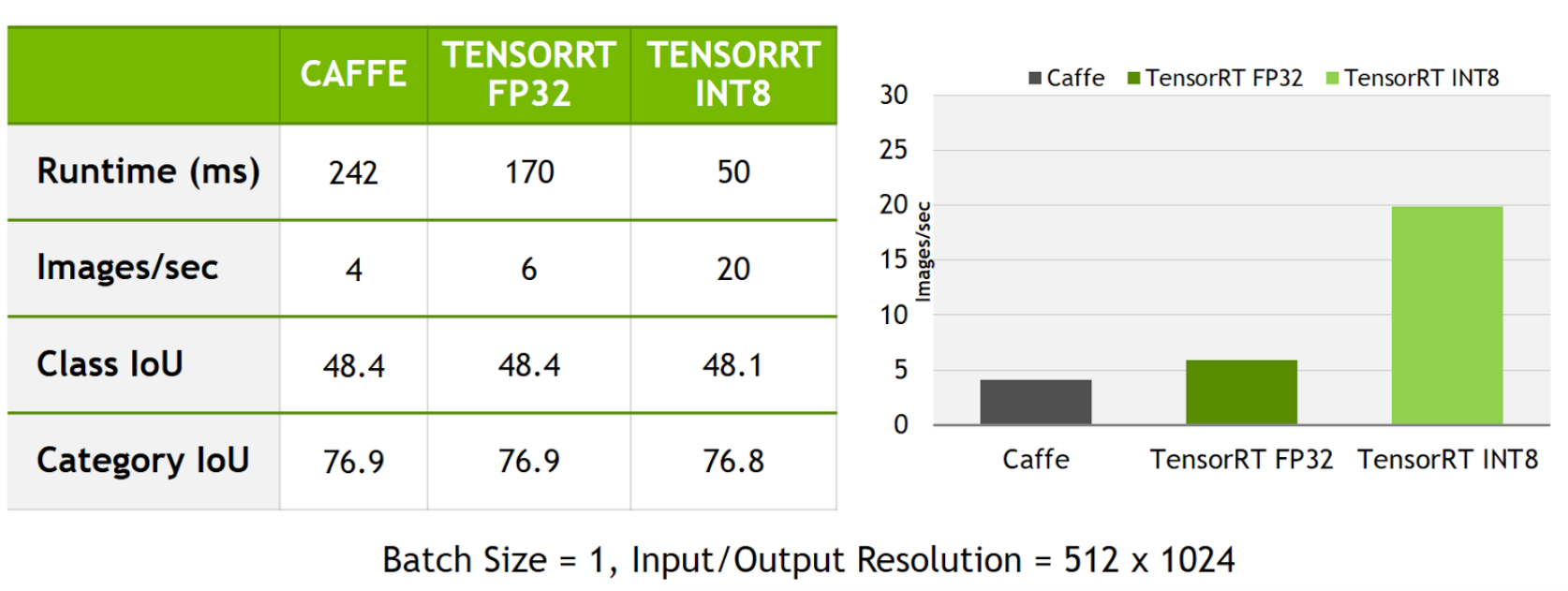
result
caffe / tensorrt FP32 / tensorrt INT8
Code
fp32
by default.
fp16
cpp
builder->setFp16Mode(true);python
builder.set_fp16_mode(True)
int8
cpp usage
builder->setInt8Mode(true); builder->setInt8Calibrator(calibrator);python usage
import tensorrt as trt NUM_IMAGES_PER_BATCH = 5 batchstream = ImageBatchStream(NUM_IMAGES_PER_BATCH,calibration_files) Int8_calibrator = trt.infer.EntropyCalibrator([“input_node_name”],batchstream) trt_builder = trt.infer.create_infer_builder(G_LOGGER) trt_builder.set_int8_mode(True) trt_builder.set_int8_calibrator(Int8_calibrator)
Int8 Calibrator
see 5.1.3.2. INT8 Calibration Using C++
Calibration can be slow, therefore, the IInt8Calibrator interface provides methods for caching intermediate data. Using these methods effectively requires a more detailed understanding of calibration.
When building an INT8 engine, the builder performs the following steps:
- Builds a 32-bit engine, runs it on the calibration set, and records a histogram for each tensor of the distribution of activation values.
- Builds a calibration table from the histograms.
- Builds the INT8 engine from the calibration table and the network definition.
The calibration table can be cached. Caching is useful when building the same network multiple times, for example, on multiple platforms. It captures data derived from the network and the calibration set. The parameters are recorded in the table. If the network or calibration set changes, it is the application’s responsibility to invalidate the cache.
The cache is used as follows:
- if a calibration table is found, calibration is skipped, otherwise:
the calibration table is built from the histograms and parameters - then the INT8 network is built from the network definition and the calibration table.
Cached data is passed as a pointer and length.
After you have implemented the calibrator, you can configure the builder to use it:
builder->setInt8Calibrator(calibrator);
The make_plan program must run on the target system in order for the TensorRT engine to be optimized correctly for that system. However, if an INT8 calibration cache was produced on the host, the cache may be re-used by the builder on the target when generating the engine (in other words, there is no need to do INT8 calibration on the target system itself).
INT8 calibration cache can be re-used, while engine can not.
demo
c++
cpp:
see calibrator.h
and calibrator.cpp
calibrator.h
#ifndef _CALIBRATOR_H_
#define _CALIBRATOR_H_
#include "NvInfer.h"
#include "ds_image.h"
#include "trt_utils.h"
class Int8EntropyCalibrator : public nvinfer1::IInt8EntropyCalibrator
{
public:
Int8EntropyCalibrator(const uint& batchSize, const std::string& calibrationSetPath,
const std::string& calibTableFilePath, const uint64_t& inputSize,
const uint& inputH, const uint& inputW, const std::string& inputBlobName);
virtual ~Int8EntropyCalibrator() { NV_CUDA_CHECK(cudaFree(m_DeviceInput)); }
int getBatchSize() const override { return m_BatchSize; }
bool getBatch(void* bindings[], const char* names[], int nbBindings) override;
const void* readCalibrationCache(size_t& length) override;
void writeCalibrationCache(const void* cache, size_t length) override;
private:
const uint m_BatchSize;
const uint m_InputH;
const uint m_InputW;
const uint64_t m_InputSize;
const uint64_t m_InputCount;
const char* m_InputBlobName;
const std::string m_CalibTableFilePath{nullptr};
uint m_ImageIndex;
bool m_ReadCache{true};
void* m_DeviceInput{nullptr};
std::vector<std::string> m_ImageList;
std::vector<char> m_CalibrationCache;
};
#endif
calibrator.cpp
#include "calibrator.h"
#include <fstream>
#include <iostream>
#include <iterator>
Int8EntropyCalibrator::Int8EntropyCalibrator(const uint& batchSize,
const std::string& calibrationSetPath,
const std::string& calibTableFilePath,
const uint64_t& inputSize, const uint& inputH,
const uint& inputW, const std::string& inputBlobName) :
m_BatchSize(batchSize),
m_InputH(inputH),
m_InputW(inputW),
m_InputSize(inputSize),
m_InputCount(batchSize * inputSize),
m_InputBlobName(inputBlobName.c_str()),
m_CalibTableFilePath(calibTableFilePath),
m_ImageIndex(0)
{
m_ImageList = loadListFromTextFile(calibrationSetPath);
m_ImageList.resize(static_cast<int>(m_ImageList.size() / m_BatchSize) * m_BatchSize);
std::random_shuffle(m_ImageList.begin(), m_ImageList.end(), [](int i) { return rand() % i; });
NV_CUDA_CHECK(cudaMalloc(&m_DeviceInput, m_InputCount * sizeof(float)));
}
bool Int8EntropyCalibrator::getBatch(void* bindings[], const char* names[], int nbBindings)
{
if (m_ImageIndex + m_BatchSize >= m_ImageList.size()) return false;
// Load next batch
std::vector<DsImage> dsImages(m_BatchSize);
for (uint j = m_ImageIndex; j < m_ImageIndex + m_BatchSize; ++j)
{
dsImages.at(j - m_ImageIndex) = DsImage(m_ImageList.at(j), m_InputH, m_InputW);
}
m_ImageIndex += m_BatchSize;
cv::Mat trtInput = blobFromDsImages(dsImages, m_InputH, m_InputW);
NV_CUDA_CHECK(cudaMemcpy(m_DeviceInput, trtInput.ptr<float>(0), m_InputCount * sizeof(float),
cudaMemcpyHostToDevice));
assert(!strcmp(names[0], m_InputBlobName));
bindings[0] = m_DeviceInput;
return true;
}
const void* Int8EntropyCalibrator::readCalibrationCache(size_t& length)
{
void* output;
m_CalibrationCache.clear();
assert(!m_CalibTableFilePath.empty());
std::ifstream input(m_CalibTableFilePath, std::ios::binary);
input >> std::noskipws;
if (m_ReadCache && input.good())
std::copy(std::istream_iterator<char>(input), std::istream_iterator<char>(),
std::back_inserter(m_CalibrationCache));
length = m_CalibrationCache.size();
if (length)
{
std::cout << "Using cached calibration table to build the engine" << std::endl;
output = &m_CalibrationCache[0];
}
else
{
std::cout << "New calibration table will be created to build the engine" << std::endl;
output = nullptr;
}
return output;
}
void Int8EntropyCalibrator::writeCalibrationCache(const void* cache, size_t length)
{
assert(!m_CalibTableFilePath.empty());
std::ofstream output(m_CalibTableFilePath, std::ios::binary);
output.write(reinterpret_cast<const char*>(cache), length);
output.close();
}
c++ v2
class Int8CacheCalibrator : public IInt8EntropyCalibrator {
public:
Int8CacheCalibrator(std::string cacheFile)
: mCacheFile(cacheFile) {}
virtual ~Int8CacheCalibrator() {}
int getBatchSize() const override {return 1;}
bool getBatch(void* bindings[], const char* names[], int nbBindings) override {
return false;
}
const void* readCalibrationCache(size_t& length) override
{
mCalibrationCache.clear();
std::ifstream input(mCacheFile, std::ios::binary);
input >> std::noskipws;
if (input.good()) {
std::copy(std::istream_iterator(input),
std::istream_iterator<char>(),
std::back_inserter<char>(mCalibrationCache));
}
length = mCalibrationCache.size();
return length ? &mCalibrationCache[0] : nullptr;
}
private:
std::string mCacheFile;
std::vector<char> mCalibrationCache;
};
python
- see calibrator.py
import pycuda.driver as cuda
import pycuda.autoinit
import numpy as np
from PIL import Image
import ctypes
import tensorrt as trt
CHANNEL = 3
HEIGHT = 512
WIDTH = 1024
class PythonEntropyCalibrator(trt.infer.EntropyCalibrator):
def __init__(self, input_layers, stream):
trt.infer.EntropyCalibrator.__init__(self)
self.input_layers = input_layers
self.stream = stream
self.d_input = cuda.mem_alloc(self.stream.calibration_data.nbytes)
stream.reset()
def get_batch_size(self):
return self.stream.batch_size
def get_batch(self, bindings, names):
batch = self.stream.next_batch()
if not batch.size:
return None
cuda.memcpy_htod(self.d_input, batch)
for i in self.input_layers[0]:
assert names[0] != i
bindings[0] = int(self.d_input)
return bindings
def read_calibration_cache(self, length):
return None
def write_calibration_cache(self, ptr, size):
cache = ctypes.c_char_p(int(ptr))
with open('calibration_cache.bin', 'wb') as f:
f.write(cache.value)
return None
Reference
- int8-inference-autonomous-vehicles-tensorrt
- 8-bit-inference-with-tensorrt
- 8-bit-inference-with-tensorrt 中文翻译版
- 基于tensorRT方案的INT8量化实现
History
- 20181119: created.



