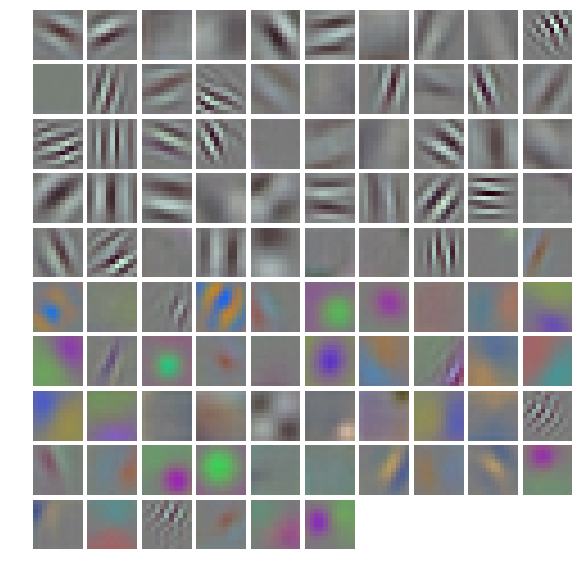
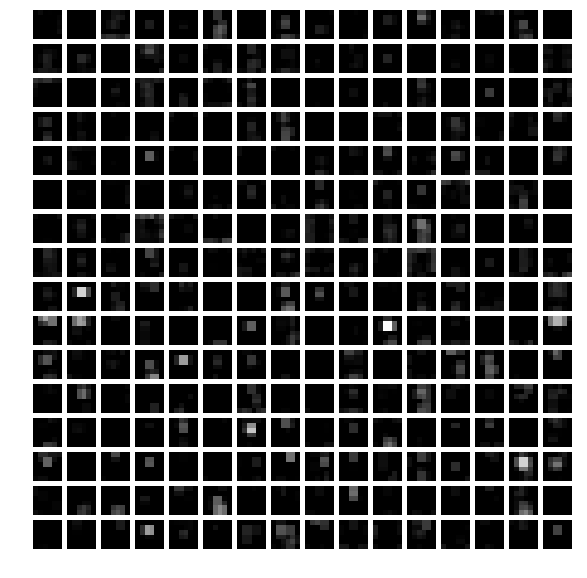
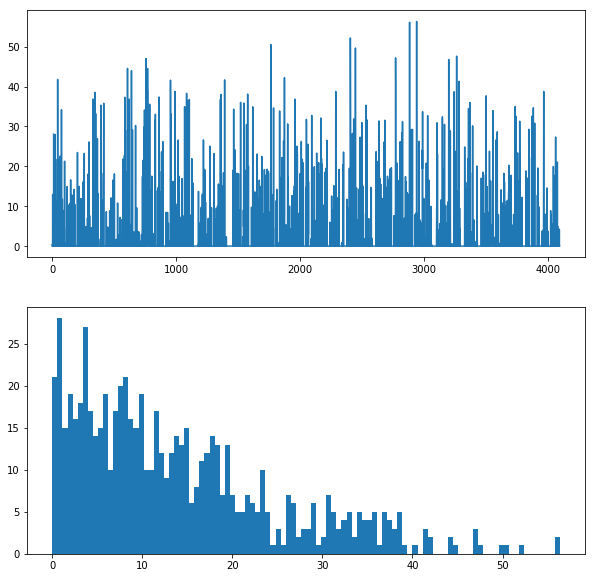
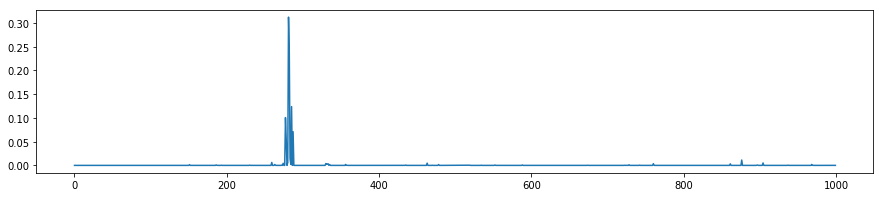
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
652
653
654
655
656
657
658
659
660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
714
715
716
717
718
719
720
721
722
723
724
725
726
727
728
729
730
731
732
733
734
735
736
737
738
739
740
741
742
743
744
745
746
747
748
749
750
751
752
753
754
755
756
757
758
759
760
761
762
763
764
765
766
767
|
"""network3.py
~~~~~~~~~~~~~~
A Theano-based program for training and running simple neural
networks.
Supports several layer types (fully connected, convolutional, max
pooling, softmax), and activation functions (sigmoid, tanh, and
rectified linear units, with more easily added).
When run on a CPU, this program is much faster than network.py and
network2.py. However, unlike network.py and network2.py it can also
be run on a GPU, which makes it faster still.
Because the code is based on Theano, the code is different in many
ways from network.py and network2.py. However, where possible I have
tried to maintain consistency with the earlier programs. In
particular, the API is similar to network2.py. Note that I have
focused on making the code simple, easily readable, and easily
modifiable. It is not optimized, and omits many desirable features.
This program incorporates ideas from the Theano documentation on
convolutional neural nets (notably,
http://deeplearning.net/tutorial/lenet.html ), from Misha Denil's
implementation of dropout (https://github.com/mdenil/dropout ), and
from Chris Olah (http://colah.github.io ).
Written for Theano 0.6 and 0.7, needs some changes for more recent
versions of Theano.
对于N=50000数据全部参与训练,time(python) = 7分钟; time(theano) = 1分钟。
But the big win is the ability to do fast symbolic differentiation,
using a very general form of the backpropagation algorithm.
This is extremely useful for applying stochastic gradient
descent to a wide variety of network architectures.
"""
import cPickle
import gzip
import time
import copy
import numpy as np
import theano
import theano.tensor as T
from theano.tensor.nnet import conv
from theano.tensor.nnet import softmax
from theano.tensor import shared_randomstreams
from theano.tensor.signal.pool import pool_2d
def linear(z): return z
def ReLU(z): return T.maximum(0.0, z)
from theano.tensor.nnet import sigmoid
from theano.tensor import tanh
def load_data_shared(filename="../data/mnist.pkl.gz",training_set_size=1000):
print 'loading data from {0} of #{1}'.format(filename,training_set_size)
f = gzip.open(filename, 'rb')
training_data, validation_data, test_data = cPickle.load(f)
f.close()
def shared(data):
"""Place the data into shared variables. This allows Theano to copy
the data to the GPU, if one is available.
shared_x.get_value().shape float32(50000, 784)
shared_y.get_value().shape float32(50000,)
y_cast = T.cast(shared_y, "int8") # float32--->int8
shared_x.type TensorType(float32, matrix) theano.tensor.sharedvar.TensorSharedVariable
shared_y.type TensorType(float32, vector) theano.tensor.sharedvar.TensorSharedVariable
y_cast.type TensorType(int32, vector) theano.tensor.var.TensorVariable (y_cast不是shared变量)
"""
shared_x = theano.shared(np.asarray(data[0][:training_set_size,],dtype=theano.config.floatX), borrow=True)
shared_y = theano.shared(np.asarray(data[1][:training_set_size], dtype=theano.config.floatX), borrow=True)
return shared_x, T.cast(shared_y, 'int8')
return [shared(training_data), shared(validation_data), shared(test_data)]
def load_data_expanded(filename="../data/mnist_expanded.pkl.gz",training_set_size=1000):
return load_data_shared(filename=filename,training_set_size=training_set_size)
class Network(object):
def __init__(self, layers, mini_batch_size):
"""Takes a list of `layers`, describing the network architecture, and
a value for the `mini_batch_size` to be used during training
by stochastic gradient descent.
"""
self.layers = layers
assert len(self.layers)>=2
self.mini_batch_size = mini_batch_size
self.params = [param for layer in self.layers for param in layer.params]
self.x = T.matrix("x")
self.y = T.bvector("y")
init_layer = self.layers[0]
init_layer.set_inpt(self.x, self.x, self.mini_batch_size)
for j in xrange(1, len(self.layers)):
prev_layer, layer = self.layers[j-1], self.layers[j]
layer.set_inpt(prev_layer.output, prev_layer.output_dropout, self.mini_batch_size)
self.output = self.layers[-1].output
self.output_dropout = self.layers[-1].output_dropout
def SGD(self, training_data, epochs, mini_batch_size, eta,
validation_data, test_data, lmbda=0.0,
no_improvement_in_n=20,use_constant_eta=True,
eta_shrink_times=10,eta_descrease_factor = 0.0001):
"""Train the network using mini-batch stochastic gradient descent."""
training_x, training_y = training_data
validation_x, validation_y = validation_data
test_x, test_y = test_data
num_training_batches = size(training_data)/mini_batch_size
num_validation_batches = size(validation_data)/mini_batch_size
num_test_batches = size(test_data)/mini_batch_size
l2_norm_squared = sum([(layer.w**2).sum() for layer in self.layers])
cost0 = self.layers[-1].cost(self)
cost = cost0 + 0.5*lmbda*l2_norm_squared/size(training_data)
grads = T.grad(cost, self.params)
shared_eta = theano.shared(eta,borrow=True)
updates = [(param, param-T.cast(shared_eta*grad,dtype=theano.config.floatX)) for param, grad in zip(self.params, grads)]
"""
grad(float32),没有指定floatX=float32,则eta*grad(float64),指定之后eta*grad(float32),无需cast
#for param, grad in zip(self.params, grads):
# print param.type,grad.type,(eta*grad).type
# updates = [(param, T.cast(param-eta*grad,'float32') ) for param, grad in zip(self.params, grads)]
"""
i = T.lscalar()
train_mb = theano.function(
[i], cost, updates=updates,
givens={
self.x:
training_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size],
self.y:
training_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size]
})
train_mb_cost = theano.function(
[i], cost,
givens={
self.x:
training_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size],
self.y:
training_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size]
})
train_mb_accuracy = theano.function(
[i], self.layers[-1].accuracy(self.y),
givens={
self.x:
training_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size],
self.y:
training_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size]
})
validate_mb_cost = theano.function(
[i], cost,
givens={
self.x:
validation_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size],
self.y:
validation_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size]
})
validate_mb_accuracy = theano.function(
[i], self.layers[-1].accuracy(self.y),
givens={
self.x:
validation_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size],
self.y:
validation_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size]
})
test_mb_cost = theano.function(
[i], cost,
givens={
self.x:
test_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size],
self.y:
test_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size]
})
test_mb_accuracy = theano.function(
[i], self.layers[-1].accuracy(self.y),
givens={
self.x:
test_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size],
self.y:
test_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size]
})
self.test_mb_predictions = theano.function(
[i], self.layers[-1].y_out,
givens={
self.x:
test_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size]
})
"""
def shuffle_data(x,y):
seed = int(time.time())
np.random.seed(seed)
np.random.shuffle(x)
np.random.seed(seed)
np.random.shuffle(y)
def shuffle_training_data(training_x,training_y):
# CPU, OK; GPU, FAILED (在GPU中borrow失效)
originX = training_x.get_value(borrow=True) # shared---> nparray
originY = training_y.get_value(borrow=True) # shared---> nparray
shuffle_data(originX,originY)
"""
evaluation_costs, evaluation_accuracys = [], []
training_costs, training_accuracys = [], []
best_epoch = 0
cur_eta_shrink_times = 0
best_validation_accuracy = 0.0
for epoch in xrange(epochs):
for minibatch_index in xrange(num_training_batches):
iteration = num_training_batches*epoch+minibatch_index
if iteration % 1000 == 0:
print("Training mini-batch number {0}".format(iteration))
cost_ij = train_mb(minibatch_index)
validation_cost = np.mean( [validate_mb_cost(j) for j in xrange(num_validation_batches)] )
validation_accuracy = np.mean( [validate_mb_accuracy(j) for j in xrange(num_validation_batches)] )
print("\nEpoch {0}: validation accuracy {1:.2%}".format(epoch, validation_accuracy))
train_cost = np.mean( [train_mb_cost(j) for j in xrange(num_training_batches)] )
train_accuracy = np.mean( [train_mb_accuracy(j) for j in xrange(num_training_batches)] )
evaluation_costs.append(validation_cost)
evaluation_accuracys.append(validation_accuracy)
training_costs.append(train_cost)
training_accuracys.append(train_accuracy)
if best_validation_accuracy - validation_accuracy < 0.0:
print("This is the best validation accuracy to date.")
best_validation_accuracy = validation_accuracy
best_epoch = epoch
best_iteration = iteration
best_net = copy.deepcopy(self)
if test_data:
test_accuracy = np.mean( [test_mb_accuracy(j) for j in xrange(num_test_batches)] )
print('The corresponding test accuracy is {0:.2%}'.format(test_accuracy))
if (epoch+1) % no_improvement_in_n == 0:
if (epoch - best_epoch) >= no_improvement_in_n:
print '!'*100
print '[HIT] Early stopping at epoch #{0},best_epoch #{1},iteration #{2},validation accuracy {3:.2%}'.format(epoch,best_epoch,best_iteration,best_validation_accuracy)
print '!'*100
break;
if use_constant_eta:
break
else:
print 'cur_eta_shrink_times = {0}'.format(cur_eta_shrink_times)
if cur_eta_shrink_times >= eta_shrink_times:
print '+'*100
print '[HIT] Eta shrink OK. at epoch #{0},best_epoch #{1},iteration #{2},validation accuracy {3:.2%}'.format(epoch,best_epoch,best_iteration,best_validation_accuracy)
print '+'*100
break;
cur_eta_shrink_times +=1
eta_descrease_factor = 0.0001
new_eta = eta/(1.0+eta_descrease_factor*(epoch+1))
shared_eta.set_value(np.asarray(new_eta,dtype=theano.config.floatX),borrow=True)
with open('best_model.pkl', 'wb') as fp:
print 'Saving best mode to best_model.pkl...'
cPickle.dump(best_net, fp)
print("\nFinished training network.")
print("Best validation accuracy of {0:.2%} obtained at best_epoch {1}".format(best_validation_accuracy, best_epoch))
print("Corresponding test accuracy of {0:.2%}".format(test_accuracy))
return evaluation_costs, evaluation_accuracys, training_costs, training_accuracys,best_epoch
def load_network_and_predict():
"""
An example of how to load a trained model and use it
to predict labels.
"""
net = cPickle.load(open('best_model.pkl'))
training_set_size = 50000
train_data,val_data,test_data = load_data_shared(training_set_size=training_set_size)
test_x,test_y = test_data
mini_batch_size = 10
num_test_batches = size(test_data)/mini_batch_size
i = T.lscalar()
test_mb_predictions = theano.function(
[i], net.layers[-1].y_out,
givens={
net.x:
test_x[i*mini_batch_size: (i+1)*mini_batch_size]
})
test_mb_accuracy = theano.function(
[i], net.layers[-1].accuracy(net.y),
givens={
net.x:
test_x[i*mini_batch_size: (i+1)*mini_batch_size],
net.y:
test_y[i*mini_batch_size: (i+1)*mini_batch_size]
})
test_predictions = test_mb_predictions(0)
print 'real values of first 10: ',test_y[:10].eval()
print 'predictions of first 10: ',test_predictions
test_accuracy = np.mean( [test_mb_accuracy(j) for j in xrange(num_test_batches)] )
print 'test_accuracy ',test_accuracy
class ConvPoolLayer(object):
"""Used to create a combination of a convolutional and a max-pooling
layer. A more sophisticated implementation would separate the
two, but for our purposes we'll always use them together, and it
simplifies the code, so it makes sense to combine them.
"""
def __init__(self, filter_shape, image_shape, poolsize=(2, 2),
activation_fn=sigmoid):
"""`filter_shape` is a tuple of length 4, whose entries are the number
of filters, the number of input feature maps, the filter height, and the
filter width.
`image_shape` is a tuple of length 4, whose entries are the
mini-batch size, the number of input feature maps, the image
height, and the image width.
`poolsize` is a tuple of length 2, whose entries are the y and
x pooling sizes.
np.prod((2,2)) = 4 # int64
ConvPoolLayer1
image_shape=(m,1,28,28) 1*28*28 (1 input feature map)
filter_shape=(20,1,5,5) 20*24*24
poolsize=(2,2) 20*12*12
ConvPoolLayer2
image_shape=(m,20,12,12) 20*12*12 (20 input feature map)
filter_shape=(40,20,5,5) 40*8*8
poolsize=(2,2) 40*4*4
ConvPoolLayer1
(20,1,5,5)
20指定当前ConvLayer1的features的数量: c1_f1,c1_f2,....c1_f19,c1_f20。
(1,5,5)指定feature的一个pixel所对应的local receptive field(LRF),此处对应1个input feature的5*5区域。
对应的w: w1,w2,...w19,w20 of size(1,5,5)===>w(20,1,5,5) filter_shape
对应的b: b1,b2,...b19,b20 of size() ===>b(20,)
ConvPoolLayer2
(40,20,5,5)
40指定当前ConvLayer2的features的数量: c2_f1,c2_f2,....c2_f39,c2_f40。
(20,5,5)指定feature的一个pixel所对应的local receptive field(LRF),此处对应20个input feature的5*5区域。
对应的w: w1,w2,...w39,w40 of size(20,5,5)===>w(40,20,5,5) filter_shape
对应的b: b1,b2,...b39,b40 of size() ===>b(40,)
"""
assert image_shape[1] == filter_shape[1]
self.filter_shape = filter_shape
self.image_shape = image_shape
self.poolsize = poolsize
self.activation_fn=activation_fn
n_in = np.prod(filter_shape[1:])
n_out = (filter_shape[0] * np.prod(filter_shape[2:]) // np.prod(poolsize))
w_bound = np.sqrt(6./(n_in+n_out))
if activation_fn == sigmoid:
w_bound = 4*w_bound
self.w = theano.shared(
np.asarray(
np.random.uniform(low=-w_bound,high=w_bound,
size=filter_shape),
dtype=theano.config.floatX),
borrow=True)
self.b = theano.shared(
np.asarray(
np.random.normal(loc=0, scale=1.0, size=(filter_shape[0],)),
dtype=theano.config.floatX),
borrow=True)
self.params = [self.w, self.b]
def set_inpt(self, inpt, inpt_dropout, mini_batch_size):
"""
inpt = x: fmatrix(m,784)
ConvPoolLayer1
image_shape=(m,1,28,28) m,1*28*28 (1 input feature map)
filter_shape=(20,1,5,5) m,20*24*24 w(20,1,5,5) b(20,)
poolsize=(2,2) m,20*12*12
ConvPoolLayer2
image_shape=(m,20,12,12) m,20*12*12 (20 input feature map)
filter_shape=(40,20,5,5) m,40*8*8 w(40,20,5,5) b(40,)
poolsize=(2,2) m,40*4*4
ConvPoolLayer1
inpt(m,784)--->inpt(m,1,28,28)
conv_out(m,20,24,24)
pooled_out(m,20,12,12)
output(m,20,12,12)
ConvPoolLayer2
inpt(m,20,12,12)
conv_out(m,40,8,8)
pooled_out(m,40,4,4)
output(m,40,4,4)
"""
self.inpt = inpt.reshape(self.image_shape)
conv_out = conv.conv2d( input=self.inpt, image_shape=self.image_shape,
filters=self.w, filter_shape=self.filter_shape)
pooled_out = pool_2d( input=conv_out, ws=self.poolsize, ignore_border=True)
b_shuffle = self.b.dimshuffle('x', 0, 'x', 'x')
self.output = self.activation_fn( pooled_out + b_shuffle )
self.output_dropout = self.output
class FullyConnectedLayer(object):
def __init__(self, n_in, n_out, activation_fn=sigmoid, p_dropout=0.0):
self.n_in = n_in
self.n_out = n_out
self.activation_fn = activation_fn
self.p_dropout = p_dropout
w_bound = np.sqrt(6./(n_in+n_out))
if activation_fn == sigmoid:
w_bound = 4*w_bound
self.w = theano.shared(
np.asarray(
np.random.uniform(low=-w_bound,high=w_bound,
size=(n_in, n_out)),
dtype=theano.config.floatX),
name='w', borrow=True)
self.b = theano.shared(
np.asarray(np.random.normal(loc=0.0, scale=1.0, size=(n_out,)),
dtype=theano.config.floatX),
name='b', borrow=True)
self.params = [self.w, self.b]
def set_inpt(self, inpt, inpt_dropout, mini_batch_size):
"""
(1) inpt,output for validating and testing
(2) inpt_dropout,output_dropout for training (output_dropout--->[cost]--->grad--->params)
以 ConvPoolLayer1(m,20,12,12),ConvPoolLayer2(m,40,4,4),[640,30,10]网络结构为例说明:
************************************************************************************************
X(m,784),Y(m,)
ConvPoolLayer1:
当前层的inpt是前一层的output,因为是第一层,所以初始化为inpt = X(m,784)
inpt(m,784)--->inpt(m,1,28,28)
conv_out(m,20,24,24)
pooled_out(m,20,12,12)
output(m,20,12,12)
ConvPoolLayer2:
inpt(m,20,12,12)
conv_out(m,40,8,8)
pooled_out(m,40,4,4)
output(m,40,4,4)
************************************************************************************************
对于FullyConnectedLayer而言,inpt是ConvPoolLayer2的output=(m,40,4,4)
================================================================================================
Layer1:
inpt=(m,40,4,4)--->inpt(m,640) a1(m,640)即:m个样本,每个样本640个neurons
output = sigmoid(input*w+b) ===> a2 = sigmoid(a1*w+b)
a2(m,30) = sigmoid( a1(m,640)* w(640,30)+ b(30,) )
Layer2:
当前层的inpt是前一层的output,即是FullyConnectedLayer1的output,包含30个hidden neurons输出 a2(m,30)
output = SOFTMAX(input*w+b) ===> a3 = SOFTMAX(a2*w+b)
a3(m,10) = SOFTMAX( a2(m,30)* w(30,10)+ b(10,) )
output是m个样本对应的10个概率,y_out是m个样本对应的真实数值。
================================================================================================
"""
self.inpt = inpt.reshape((mini_batch_size, self.n_in))
self.output = self.activation_fn(T.dot(self.inpt, self.w) + self.b)
self.inpt_dropout = dropout_layer( inpt_dropout.reshape((mini_batch_size, self.n_in)), self.p_dropout)
self.output_dropout = self.activation_fn(T.dot(self.inpt_dropout, self.w) + self.b)
class SoftmaxLayer(object):
def __init__(self, n_in, n_out, p_dropout=0.0):
self.n_in = n_in
self.n_out = n_out
self.activation_fn = softmax
self.p_dropout = p_dropout
self.w = theano.shared(
np.zeros((n_in, n_out), dtype=theano.config.floatX),
name='w', borrow=True)
self.b = theano.shared(
np.zeros((n_out,), dtype=theano.config.floatX),
name='b', borrow=True)
self.params = [self.w, self.b]
def set_inpt(self, inpt, inpt_dropout, mini_batch_size):
"""
(1) inpt,output for validating and testing
(2) inpt_dropout,output_dropout for training (output_dropout--->[cost]--->grad--->params)
在Python中,a = sigmoid(w*a+b), w=(30,784),a=(784,1)一次使用一个样本参与计算。
在Theano中修改为,a = sigmoid(a*w+b) a=(m,784),w=(784,30)一次使用m个样本参与计算。
以[784,30,10]网络结构为例说明:
Layer1:
当前层的inpt是前一层的output,因为是第一层,所以初始化为a1 = X(m,784) Matrix,每一个样本包含784个输入neurons
output = sigmoid(input*w+b) ===> a2 = sigmoid(a1*w+b)
a2(m,30) = sigmoid( a1(m,784)* w(784,30)+ b(30,) )
Layer2:
当前层的inpt是前一层的output,即是FullyConnectedLayer的output,包含30个hidden neurons输出 a2(m,30)
output = SOFTMAX(input*w+b) ===> a3 = SOFTMAX(a2*w+b)
a3(m,10) = SOFTMAX( a2(m,30)* w(30,10)+ b(10,) )
output是m个样本对应的10个概率,y_out是m个样本对应的真实数值。
"""
self.inpt = inpt.reshape((mini_batch_size, self.n_in))
self.output = self.activation_fn(T.dot(self.inpt, self.w) + self.b)
"""
input--> output ---> y_out
X1---> [y0,y1,...y9] ---> 1
X2---> [y0,y1,...y9] ---> 0
...
Xm---> [y0,y1,...y9] ---> 2
axis沿着row作为一个整体进行,y_out作为最终的输出=vector(m,)。
"""
self.y_out = T.argmax(self.output, axis=1)
self.inpt_dropout = dropout_layer( inpt_dropout.reshape((mini_batch_size, self.n_in)), self.p_dropout)
self.output_dropout = self.activation_fn(T.dot(self.inpt_dropout, self.w) + self.b)
def cost(self, net):
"Return the log-likelihood cost."
"""
使用output_dropout用于train
(1) 一个样本对应的代价Cx
C = -log(a[i])
i = np.argmax(y) # a(10,1) y(10,1)
return -np.log(a[i,0])
(2) m个样本的平均代价
计算代价的时候,传递Network作为参数,方便获取net.y
output(m,10) net.y cost
X1---> [y0,y1,...y9] ---> 1 -log a[1,1]
X2---> [y0,y1,...y9] ---> 0 -log a[2,0]
Xm---> [y0,y1,...y9] ---> 2 -log a[m,2]
a = np.array([[0, 0.8, 0, 0,...],
[0.9, 0, 0, 0,...],
[0, 0, 0.7, 0...]])
y = [1,0,2]
a[[0,1,2],y]
> array([ 0.8, 0.9, 0.7])
"""
m = net.y.shape[0]
rows = T.arange(m)
return -T.mean(T.log( self.output_dropout[rows, net.y] ))
def accuracy(self, y):
"Return the accuracy for the mini-batch."
"""
使用output,y_out用于test
y(m,) 对应m个样本的真实结果
y_out(m,) 对应m个样本的预测结果
如果mini_batch_size = 5
y = np.array([2,1,7,8,9])
y_out = np.array([2,1,7,6,9])
np.mean(np.equal(y,y_out)) # [1,1,1,0,1] 0.80
"""
return T.mean(T.eq(y, self.y_out))
def size(data):
"Return the size of the dataset `data`."
return data[0].get_value(borrow=True).shape[0]
def dropout_layer(layer, p_dropout):
"""
对于[784,30,10]
Layer1:
layer= float32 (m,784), p_dropout = 0.2,对每个节点以一定的概率进行drop
参考:http://www.jianshu.com/p/ba9ca3b07922
Inverted Dropout
我们稍微将 Dropout 方法改进一下,使得我们只需要在训练阶段缩放激活函数的输出值,而不用在测试阶段改变什么。
这个改进的 Dropout 方法就被称之为 Inverted Dropout 。
在各种深度学习框架的实现中,我们都是用 Inverted Dropout 来代替 Dropout,因为这种方式有助于模型的完整性,
我们只需要修改一个参数(保留/丢弃概率),而整个模型都不用修改。
"""
srng = shared_randomstreams.RandomStreams( np.random.RandomState(0).randint(999999) )
retain_prob = 1. - p_dropout
mask = srng.binomial(n=1, p=retain_prob, size=layer.shape,dtype=theano.config.floatX)
mask_layer = layer*mask
return mask_layer/retain_prob
|